New Product: AI Evaluations
Today, we’re introducing a commercial product: AI Evaluations. This service offers enterprises, model labs, and developers comprehensive evaluation services grounded in real-world human feedback, showing how models actually perform in practice.
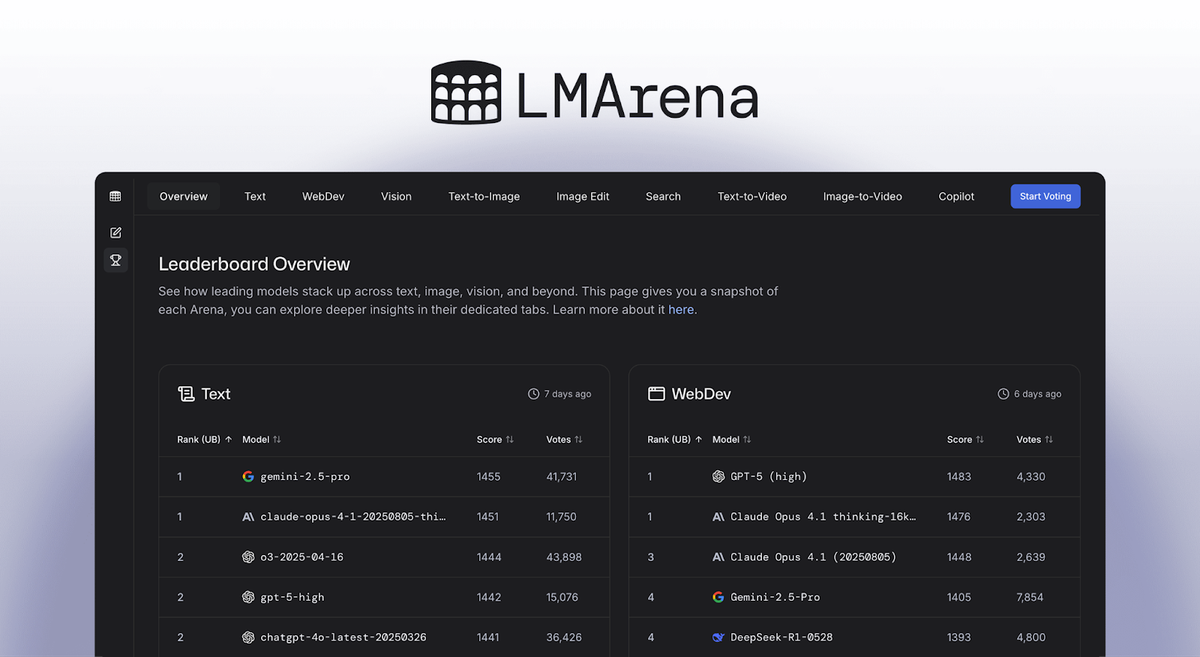
At LMArena, our mission is to improve the reliability of AI applications and systems. The majority of these applications involve a human in the loop: from coding assistants to customer-support bots to everyday chat tools. Studying those interactions at scale is critical to making AI more effective.
As more users join the platform, we’re building the infrastructure and methods to capture this complexity and turn real-world interactions into reliable insights the ecosystem can learn from.
Today, we’re introducing a commercial product: AI Evaluations. This service offers enterprises, model labs, and developers comprehensive evaluation services grounded in real-world human feedback, showing how models actually perform in practice. By providing analytics based on community feedback, we are giving them the tools they need to understand strengths, weaknesses, and tradeoffs—and, ultimately, to improve their models and AI applications for everyone.
What the Product Is
LMArena’s AI Evaluations include:
- Comprehensive, in-depth evaluations based on feedback from our community
- Auditability through representative samples of feedback data
- Service-level agreements (SLA) with committed delivery timelines for evaluation results
These features are designed to support both commercial labs and open source teams looking to better understand how their models perform in the wild.
Why Evaluation Matters
AI evaluation is critical for the entire ecosystem. Labs use LMArena feedback to build more reliable models. Developers use it to choose the best tools for their work. And the community benefits from AI that performs better in real-world use.
LMArena has already logged 250M+ real conversations, 2M+ monthly votes, and has 3M+ monthly users. We operate at a scale that makes our signal uniquely trustworthy. That’s why leading labs are turning to us—not just for transparency, but to accelerate progress for everyone.
Our Commitments
As we expand into commercial evaluations, LMArena’s core values remain unchanged:
- Neutrality. All models—commercial, open source, public, or awaiting release—are evaluated using the same community-driven methodology, with no preferential treatment.
- Breadth. A sizable portion of model sampling will always be dedicated to publicly available and open source models.
- Openness. Key datasets and foundational research will remain publicly available.
- Access. We’ll continue to support open-weight models and nonprofit institutions through flexible pricing, ensuring that organizations of any size can participate in our evaluation services.
The LMArena leaderboard will always be shared freely to the world as a public service, and all publicly released models will be evaluated according to the same fair methodology regardless of any commercial interest.
What’s Next
The public leaderboard, head-to-head battles, and open access to the best AI models will always be here for the community. Your votes, your feedback, and your curiosity are what make this platform thrive. We’re rolling out more features and more models in the coming weeks—so stay tuned!
Want to get involved or learn more about our model evaluation services?
📩 Reach out to us: evaluations@lmarena.ai
🔍 Explore the platform: https://lmarena.ai