Catch me if you can! How to beat GPT-4 with a 13B model
Authors
Shuo Yang*
Wei-Lin Chiang*
Lianmin Zheng*
Joseph E. Gonzalez
Ion Stoica
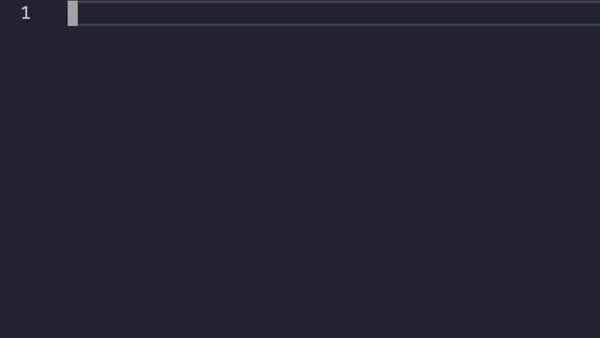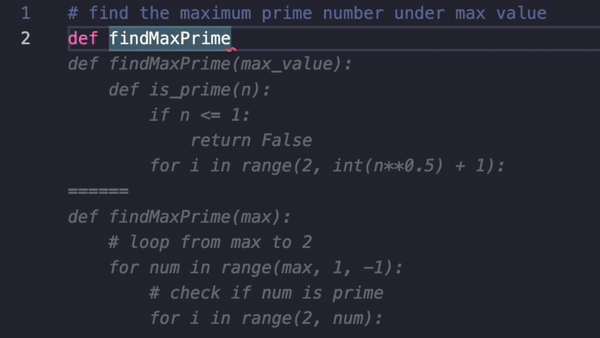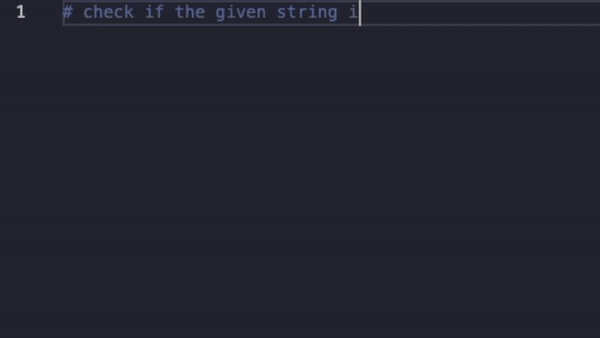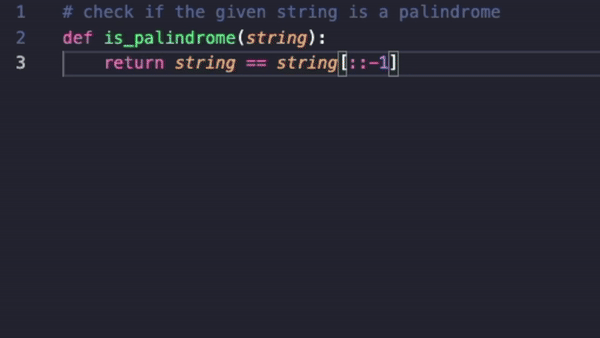
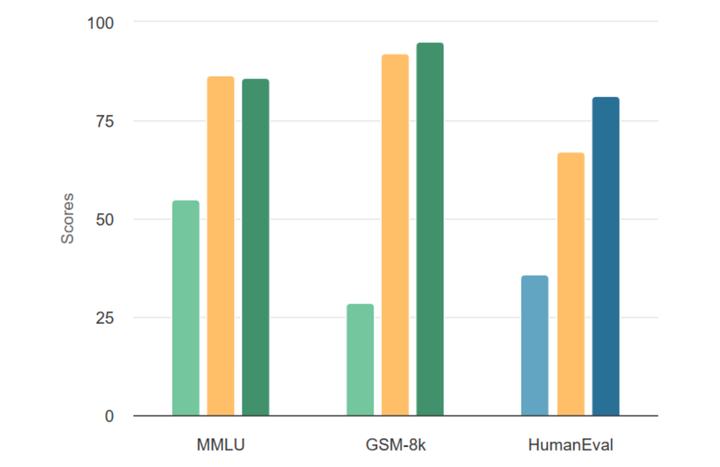
Announcing Llama-rephraser: 13B models reaching GPT-4 performance in major benchmarks (MMLU/GSK-8K/HumanEval)! To ensure result validity, we followed OpenAI’s decontamination method and found no evidence of data contamination.
What’s the trick behind it? Well, rephrasing