The Next Stage of AI Coding Evaluation Is Here
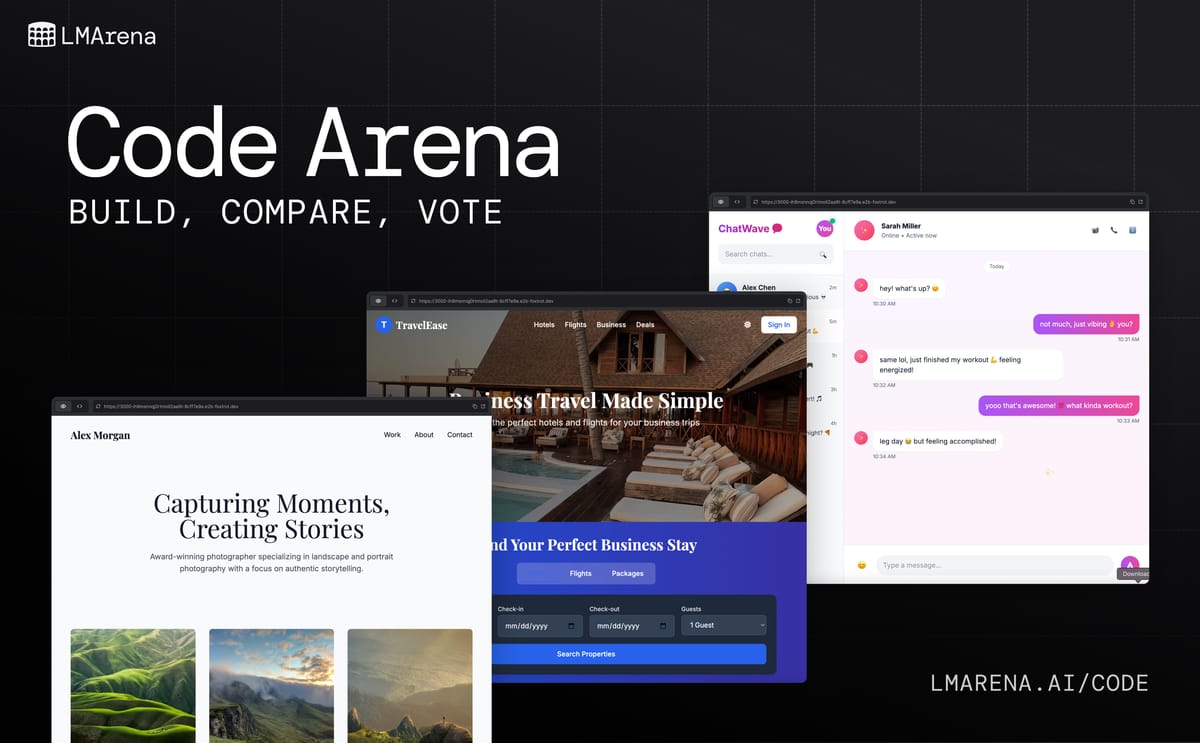
Introducing Code Arena: live evals for agentic coding in the real world
AI coding models have evolved fast. Today’s systems don’t just output static code in one shot. They build. They scaffold full web apps and sites, refactor complex systems, and debug themselves in real time. Many now act as coding agents, planning and executing structured actions to design and deploy complete applications.
But the question is no longer Can a model write code? It’s How well can it build real applications end-to-end?
Traditional benchmarks measure correctness: whether code compiles and passes a set of static test cases. Correctness matters, but it’s only part of what defines real development. Building software is iterative and creative: you plan, test, refine, and repeat. A credible evaluation must reflect that process.
Code Arena does exactly that. It’s our next-generation evaluation system, rebuilt from the ground up for transparency, precision, and real-world performance. Models operate as interactive agents inside controlled, isolated environments where every prompt, render, and action is logged. Sessions are restorable and persistent across visits, and generations can be shared or revisited later.
The result is a live, inspectable system that evaluates not only whether code works, but how well it performs, how naturally it interacts, and how faithfully it fulfills the intended design. Code Arena measures coding in motion, capturing how models think, plan, and build in conditions that mirror real development.
What’s new for developers
Code Arena introduces a developer experience built to feel like a live coding environment: interactive, transparent, and persistent from start to finish.
- Agentic behaviors: Models plan and execute autonomously using structured tool calls (create_file, edit_file, read_file) that reveal reasoning step-by-step.
- Multi-turn, multi-step execution: Models iterate, edit, and refine across multiple interactions, enabling complex builds within a single evaluation.
- Real-time generation: Output renders as models build, so developers can explore running apps while code evolves.
- Persistent sessions: Code sessions are restorable and persistent across visits, preserving state and enabling collaborative review.
- Recursive edits and HTML file trees: Every generation includes a full project structure (HTML, CSS, JS) letting evaluators inspect how models manage interdependent files and recursive edits.
- Shareable generations: Each build can be shared via a unique link for peer testing or model comparison.
- Unified workflow: Prompting, generation, and evaluation now happen entirely inside Arena’s infrastructure, ensuring controlled environments, consistent parameters, and reproducible results.
Together, these updates turn benchmarking into an experiment you can see, run, and share. Code Arena is now a transparent coding environment for developers, model builders, prototypers, knowledge workers, creative professionals, and more.
How Code Arena works
Each Code Arena evaluation is a reproducible experiment that captures the full trajectory of AI-assisted development, from ideas to generation to human judgment.
- Prompt: An evaluator or developer submits a task such as “Build a markdown editor with dark mode.”
- Plan: Models interpret the request and decide which actions to take using structured tool calls. This agentic planning mirrors real developer workflow.
- Generate: The model produces live, deployable web apps and sites.
- Record: Every model action (file creation, edit, or execution) is logged and versioned. Snapshots are stored in Cloudflare R2 and linked to Arena’s database for transparent traceability.
- Render: The resulting app is streamed through a secure frontend using CodeMirror 6 for source view and a live preview for interaction and testing.
- Vote: Evaluators compare outputs pairwise, assessing functionality, usability, and fidelity as well as design, taste, and aesthetics. Each vote is stored with full context: model version, latency, and environment.
- Aggregate: Structured human judgments feed into the leaderboard in real time, displaying confidence intervals and performance variance rather than static averages.
This closed-loop pipeline, from prompt to live app to verifiable vote, ensures that every result in Code Arena is transparent, reproducible, and scientifically grounded. Code Arena doesn’t just refine how we evaluate AI coding models. It redefines the foundation itself.
From WebDev Arena to Code Arena
When we launched WebDev Arena, it introduced the first large-scale, human-in-the-loop benchmark for AI coding. Developers could watch models build real applications, interact with outputs, and vote on performance, making evaluation participatory and transparent.
As usage scaled, so did the need for precision and reproducibility. The original system, designed for experimentation, couldn’t support the rigor required for real world usage and evaluation.
Code Arena rebuilds that foundation from the ground up. Every component has been redesigned for transparency, traceability, and methodological control. The result is a more robust and scientifically grounded system that measures not just if code works, but how well it works in practice.
Inside the rebuild
Code Arena isn’t just an infrastructure upgrade. It’s a new evaluation framework built for reproducibility, transparency, and scientific rigor. Each evaluation runs inside a tightly controlled environment designed for precision and scale, where every action, render, and result is logged and reproducible.
- Agentic tool use: Models autonomously create, modify, and execute code through structured tool calls, enabling real-world behaviors like recursive edits and dependency management.
- Persistent and shareable sessions: Code sessions are restorable and persistent across visits, allowing users to revisit, inspect, and distribute live generations.
- Reproducibility: Every prompt, model version, and human vote is linked to a traceable ID.
- Scoring framework: Results combine structured human evaluation with transparent statistical aggregation, including inter-rater reliability and confidence intervals.
This combination turns Code Arena from a leaderboard into a scientific measurement system where every number is reproducible, every output is verifiable, and every model can be tested under real-world conditions.
Unified evaluation system and methodology
Prompting, generation, comparison, and voting now happen within the Arena platform in one seamless workflow. This integration reduces latency, improves reliability, and allows precise tracking across thousands of simultaneous tasks.
With Code Arena, we didn’t just update the interface. We rebuilt the foundation of coding evaluation. Each model is scored on three axes that mirror real developer judgment:
- Functionality: Does the app do what it’s supposed to?
- Usability: Is it clear, responsive, and intuitive?
- Fidelity: Does it match the requested design or behavior?
The new system introduces agentic, multi-turn execution, where models plan and execute actions autonomously. Each model can call tools like create_file, edit_file, and run_command, recursively refining its own work in structured steps. This enables complex, iterative development cycles that mirror real engineering behavior.
Models generate and deploy fully interactive web applications and sites, and each evaluation records the complete chain, from prompt to final render, under consistent conditions, ensuring that results are traceable, auditable, and repeatable.
Evaluations remain human-driven but now apply structured scoring and transparent aggregation, producing results that are statistically validated and reproducible. This rebuild lays the foundation for Code Arena’s evolved evaluation framework, grounded in three principles:
- Humans at the core: Every score represents human judgment. Votes are logged with context and aggregated transparently.
- Show our work: Every metric links to its data: cost, latency, and methodology. Transparency is built into the infrastructure.
- Embrace uncertainty: Arena publishes confidence intervals and variance, not just averages. Evaluation should reflect nuance, not obscure it.
Clean data foundation and new leaderboard
Because Code Arena’s architecture and evaluation methodology have been completely rebuilt, it launches on a fresh leaderboard designed to reflect this new system from the ground up. No data is merged or retrofitted from WebDev Arena, ensuring methodological consistency and preserving the integrity of future comparisons.
Merging results from WebDev Arena would compromise data integrity by combining evaluations produced under different scoring systems, environments, and assumptions. Starting fresh allows Code Arena to mature under clear, reproducible evaluation rules, free from legacy bias and aligned with our rigorous standards for transparency and auditability.
The original WebDev Arena leaderboard (WebDev Legacy) will be retired in the near future, but for now, it remains live as a historical record of the first era of AI coding evaluation. The new WebDev V2 leaderboard, which underpins Code Arena, defines the forward-looking standard for real-world performance.
Bias tracking and data integrity
Every UI or workflow change can shift human voting patterns. Arena treats this as part of the science of evaluation. Before any change is integrated, the team runs bias audits, measuring effects on voting behavior and compensating for them before leaderboard updates. This ensures that human-in-the-loop evaluation remains consistent, fair, and statistically sound as the platform evolves.
Community at the core
Arena’s strength has always been its community: the developers, researchers, and builders who believe progress should be open, measurable, and shared. Code Arena turns that belief into practice.
Inside the platform, real participants drive every evaluation. Developers explore live apps, compare outputs, and decide which models perform best in real scenarios. Their collective feedback forms the data that powers the leaderboard. Human judgment is transformed into structured insight.
The Arena Discord community keeps this loop active. It’s where developers propose new challenges, join live tests, and surface anomalies that help refine the framework itself. This collaboration ensures that Code Arena evolves with the ecosystem it measures.
The Arena Creator Community extends that spirit, showcasing how people use, test, and build with Arena. Their projects make evaluation not just open and transparent, but engaging and creative.
When people take part in Code Arena, they’re not just generating data. They’re defining what good AI coding looks like.
What’s next
Code Arena’s launch marks the beginning of a new phase focused on depth, reliability, and reach. Over the coming months, the team will continue to refine data quality, latency, and evaluation speed while expanding what models can build and how developers interact with them.
The next wave of updates will introduce multi-file React applications, allowing models to generate structured repositories instead of single-file prototypes, bringing Code Arena closer to real-world software development: iterative, layered, and visual.
Within the coming months, Arena will begin rolling out agent support and multimodal inputs as well as isolated sandboxes for multi-file projects. These extensions move Code Arena toward connected, collaborative environments that mirror how modern coding agents actually work across systems, interfaces, and media.
Code Arena isn’t a static benchmark. It’s a living system, evolving with every new model, experiment, and human vote. Each update strengthens its foundation: transparent, reproducible evaluation built for scale.
Arena’s mission has always been to measure what matters: how AI performs in the real world. With Code Arena, that mission now reaches the heart of software creation. This is where developers, researchers, and model builders meet to test performance together.
The next stage of AI coding evaluation is here.
Welcome to Code Arena.