
Copilot Arena
Copilot Arena has been downloaded 2.5K times on the VSCode Marketplace, served over 100K completions, and accumulated over 10K code completion battles.
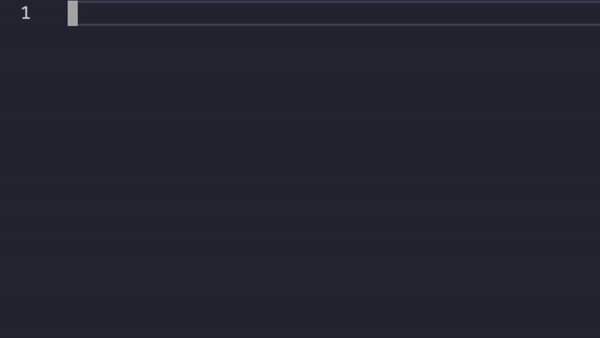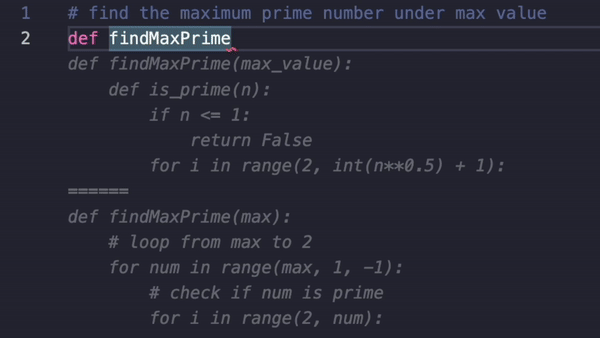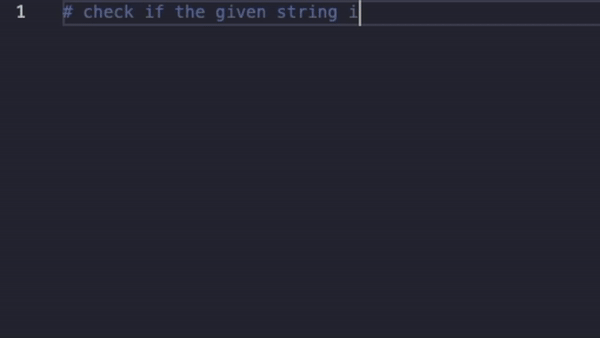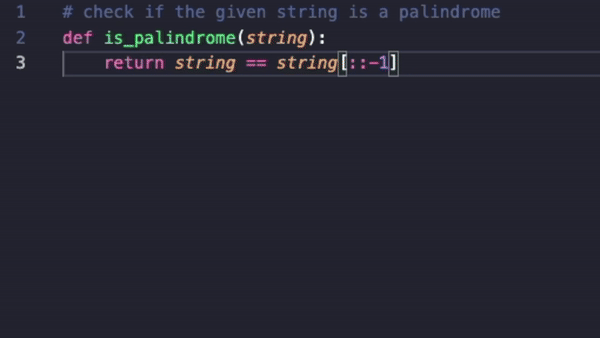
Copilot Arena's Initial Leaderboard, Insights, and a New Prompting Method for Code Completions
Contributors:
Wayne Chi
Valerie Chen
Anastasios N. Angelopoulos
Wei-Lin Chiang
Naman Jain
Tianjun Zhang
Ion Stoica
Chris Donahue
Ameet Talwalkar
Introduction
As LLMs are embedded more and more within production workflows, it’s time to rethink how we measure LLM capabilities to better reflect real-world usage. A few weeks ago, we launched Copilot Arena, a free AI coding assistant that provides paired responses from different state-of-the-art LLMs. We first introduced paired code completions and more recently rolled out inline editing-a feature where users can highlight code segments, write a prompt, and receive two diff-based suggestions for modifying that code.
Thus far, Copilot Arena has been downloaded 2.5K times on the VSCode Marketplace, served over 100K completions, and accumulated over 10K code completion battles. In this blog post, we’ll cover:
- Initial Leaderboard and Results. Our preliminary results for the code completions leaderboard and analysis of model tiers.
- Copilot Arena Usage. Analysis on Copilot Arena usage, including the distribution of coding languages, context lengths, and an initial inspection into position bias.
- Prompting. Details of how we use chat models like Claude Sonnet 3.5 and GPT-4o to perform code completions (spoiler alert, we generate code snippets and post-process!).
Initial Leaderboard and Results
As an initial set of models, we selected 9 of the best models across multiple model providers that include both open, code-specific, and commercial models. To ensure a fair comparison between models, we do the following…
- We randomize whether models appear at the top or bottom for each completion along with which models are paired for each battle.
- We show both completions at the same time. This means that a faster model completion needs to wait for the slower model.
- Many of the models with superior coding capabilities are chat models. As discussed later in the post, we optimize the prompts so they can perform code completions. We manually verified there were no significant formatting issues in the data collected.
- We set the same max number of output tokens, input tokens, top-p, and temperature (unless specified by the model provider).
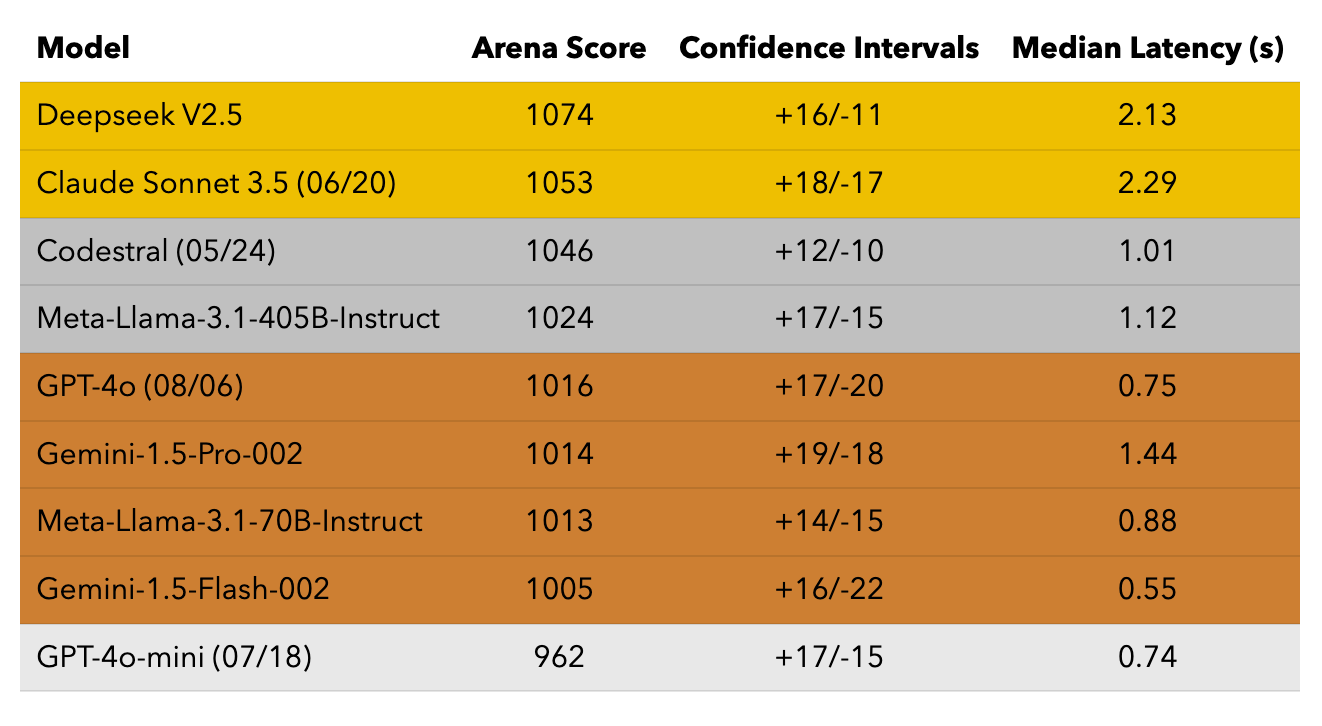
Table 1 presents the current code completion leaderboard and stratifies them into tiers. Here are our main takeaways:
- With a minor prompt tweak, Claude is able to compete with code-specific models (e.g., Deepseek V2.5) on code completion tasks, including ones that require “fill-in-the-middle”. From the beginning, we observed that these Claude and DeepSeek models have emerged as top contenders and separated themselves from the rest of the pack.
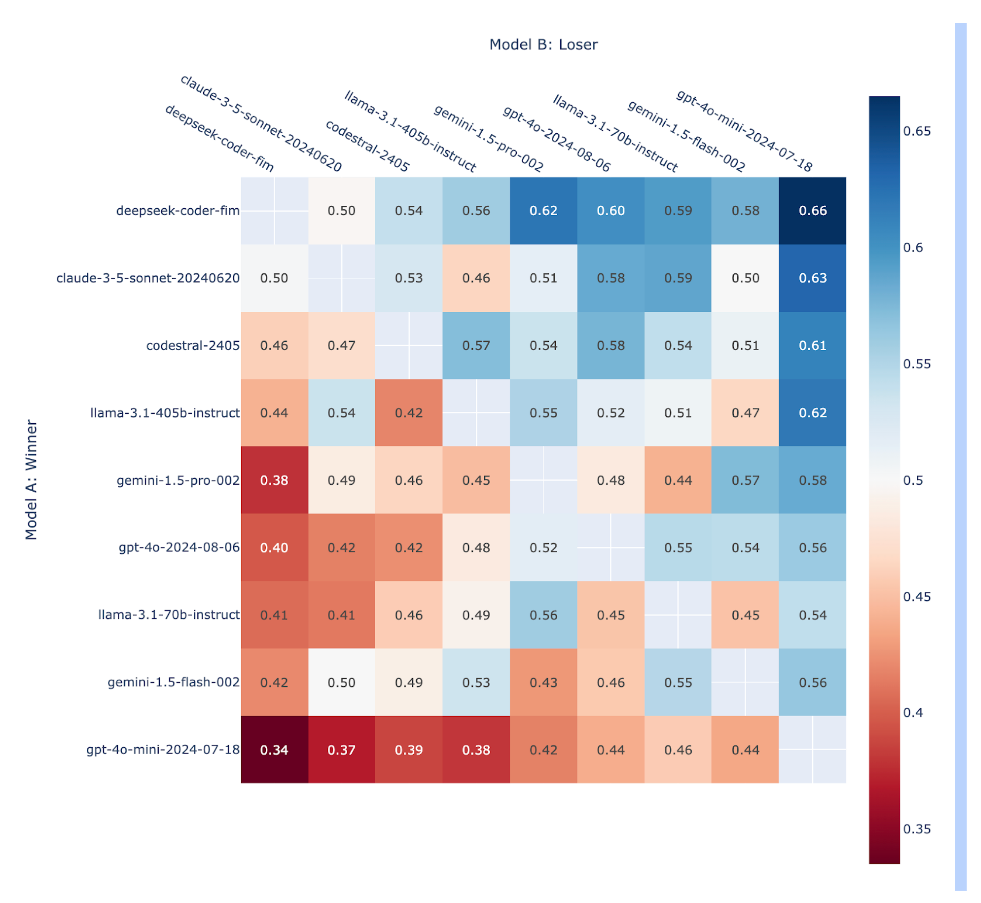
- Within a tier, we still observe slight fluctuations as we obtain more votes. Check out Figure 2 for a breakdown of the win rate percentage for each pair of models.
- We find that GPT-4o-mini is much worse than all other models.
We follow the same leaderboard computation as the latest version of Chatbot Arena, which is based on learning Bradley-Terry coefficients that minimize loss when predicting whether one model will beat the other. Please check out this blog post for a more in-depth description.
The Effect of Latency
While the Arena scores (Table 1) do not explicitly factor in model latency since both completions are shown simultaneously, we explore whether Arena Scores correlate with latency. We include median latency as a separate column in the results. In general, we find that people don’t necessarily prefer faster models. However, this may be partially because code completions are only generated in Copilot Arena after a user pauses.
How do people use Copilot Arena?
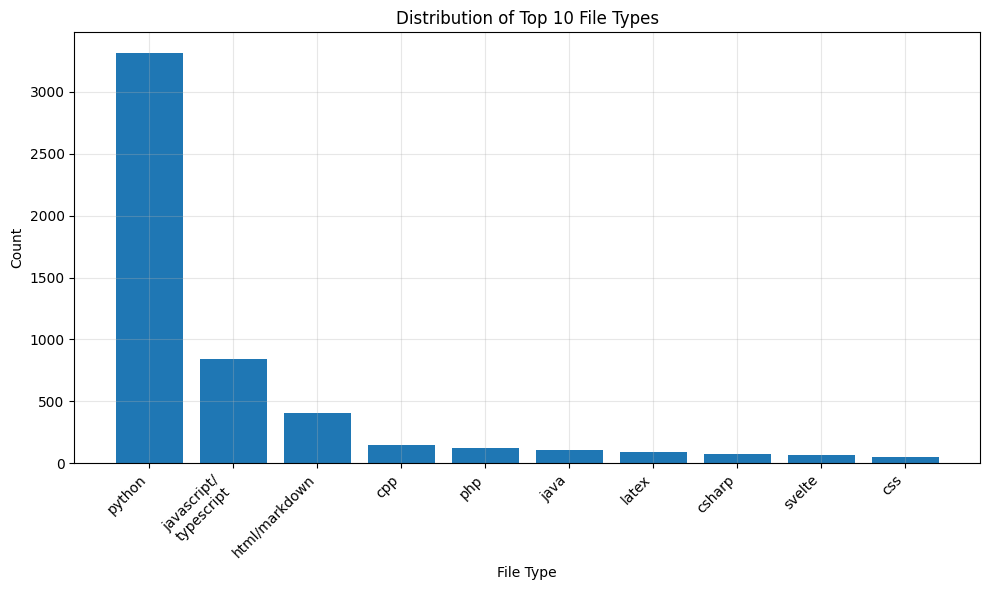
What kind of languages do people code in?
Most current Copilot Arena users code in Python, followed by javascript/typescript, html/markdown, and C++. This statistic is determined based on the file extension.
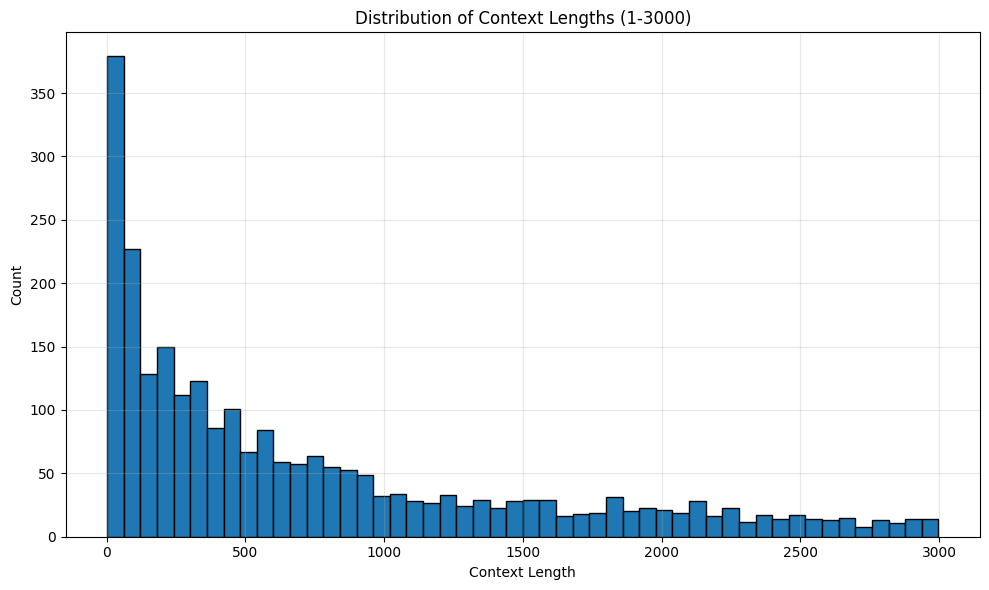
What kind of context lengths are we looking at?
The mean context length is 1002 tokens and the median is 560 tokens. This is much longer than tasks considered in existing static benchmarks. For example, human eval has a median length of ~100 tokens.
Are people biased towards the top completion? Yes. In fact, 82% of accepted completions were the top completion. We are still analyzing our data, but here are some of our insights.
- Are people even reading the completions? Or are they just instinctively pressing Tab? Users take a median of 7 seconds to view the response and then select a response. As such, we believe that people are indeed reading the completions.
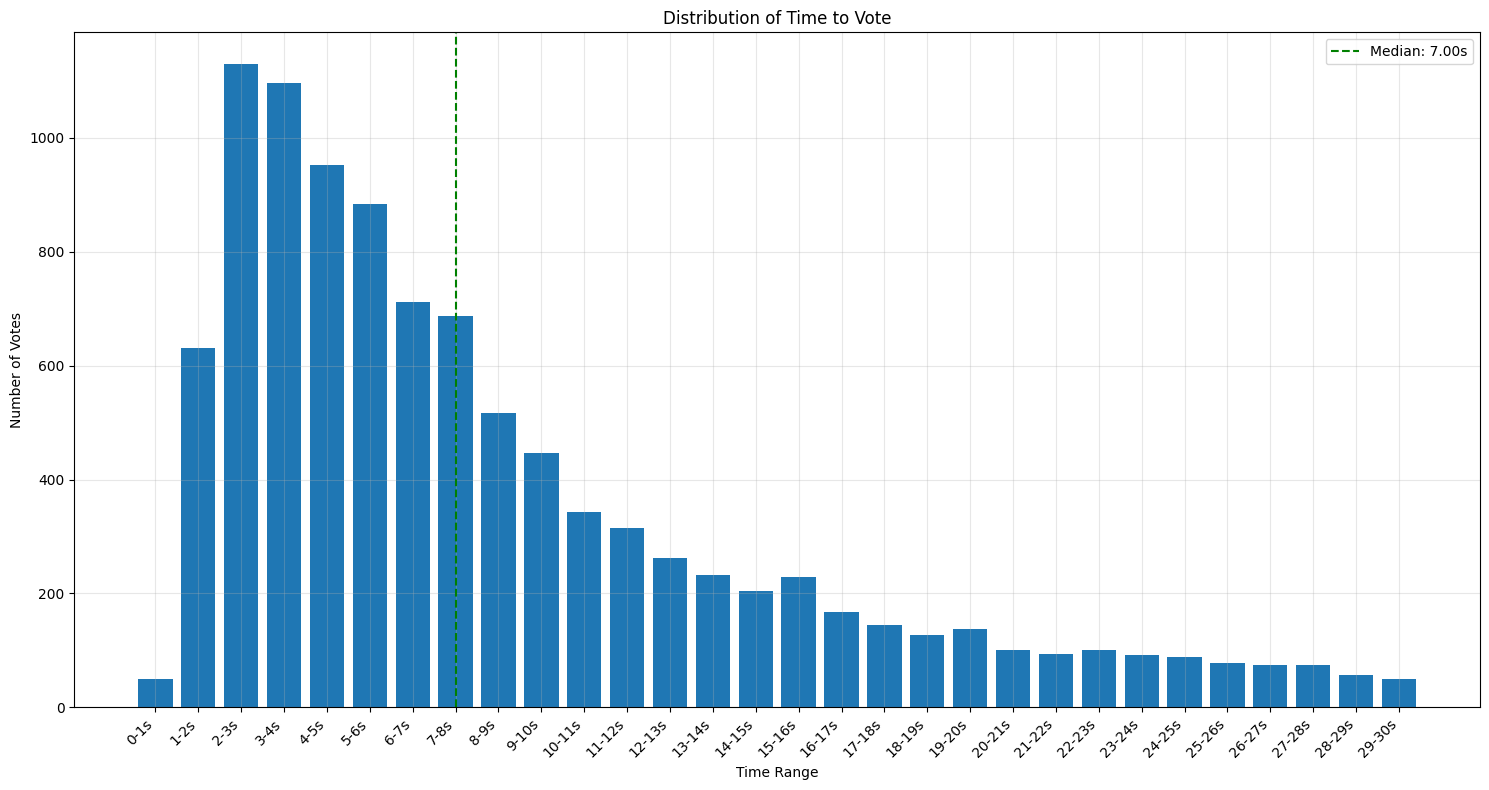
- Does position bias affect models equally? Surprisingly, no! For example, when shown as the bottom completion, Sonnet-3.5 is accepted 23.4% of the time compared to only 12.8% of the time for Gemini Flash. On the other hand, they are accepted at roughly the same rate when shown as the top completion (86.7% vs 85% respectively). We are still exploring the reasons behind this phenomenon and will continue our analysis in a future post.
How many people are regular users? In total, we have had votes from 833 unique users and between 200-250 daily active users.
How do you handle ties in Arena? We do not currently have an option for people to select that both responses are equally good (or bad).
How do you handle models pre-trained on FiM? For Deepseek V2.5 and Codestral, we use their API which directly allows for FiM capabilities.
How Do We Prompt Chat Models to Perform Code Completions?

During real development processes, developers frequently modify or expand on existing code, rather than only write code in a left-to-right manner. As such, “fill in the middle” (FiM) capabilities when generating code completions are critical for any models to be used in Copilot Arena. Many code-specific models, including DeepSeek and Codestral, are specifically trained to perform FiM. However, most models in Copilot Arena are not because they are chat models, and thus, they struggle to appropriately format a completion when provided with the prefix and suffix. We explore a simple prompting trick that allows chat models to perform code completions with high success.
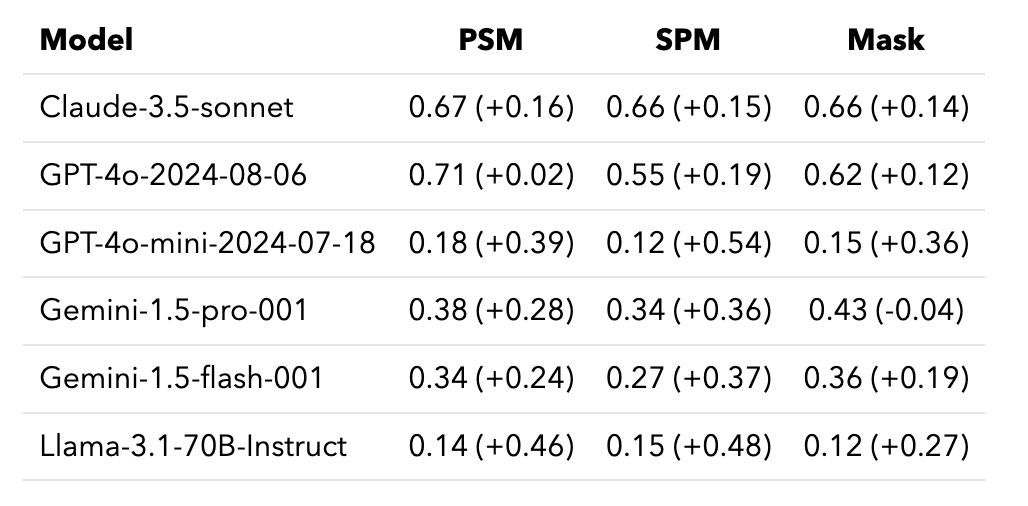
Evaluation Set-up. To verify that chat models would indeed struggle to perform FiM, we use the HumanEval-infilling dataset as an imperfect proxy to benchmark chat models’ FiM capabilities. We adopt three prompt templates considered in prior work (e.g., Gong et al.) like Prefix-suffix-middle (PSM), Suffix-prefix-middle (SPM), and Mask. Instead of measuring pass@1, we only consider whether the returned infilled code is formatted correctly.
Chat models can’t naively FiM. Table 2 shows that standard prompt templates are insufficient for chat models to complete FiM tasks. This is not necessarily an indication that models cannot code as clearly many SOTA chat models are proficient coders. Instead, the vast majority of the errors resulted from issues in formatting or duplicate code segments rather than logical errors, indicating that these models cannot generalize their code outputs to FiM tasks. While it is not feasible to retrain these models, we explore alternative approaches via prompting to enable models to complete FiM tasks.
Our solution significantly reduces formatting errors. Instead of forcing chat models to output code in a format unaligned with its training (e.g. FiM), we allow the model to generate code snippets, which is a more natural format, and then post-process them into a FiM completion. Our approach is as follows: in addition to the same prompt templates above, the models are provided with instructions to begin by re-outputting a portion of the prefix and similarly end with a portion of the suffix. We then match portions of the output code in the input and delete the repeated code. As you can see in Table 2, the models make much fewer formatting issues. These benefits hold regardless of the prompt template.
What’s next?
- More results and analyses: We’re working on adding new metrics that will provide more insight into how useful models are (e.g., code persistence), and more fine-grain analyses to understand why some models are preferred by users over others. We will also release a leaderboard for inline editing once we have collected enough votes!
- Opportunities to contribute to Copilot Arena: While our initial prompting efforts are proving to be usable in practice, we welcome suggestions for prompt improvements. In general, we are always looking to improve Copilot Arena. Ping us to get involved!
Citation
@misc{chi2024copilot,
title={Copilot Arena},
author={Wayne Chi and Valerie Chen and Wei-Lin Chiang and Anastasios N. Angelopoulos and Naman Jain and Tianjun Zhang and Ion Stoica and Chris Donahue and Ameet Talwalkar}
year={2024},
}


