
Leaderboard Changelog

This page documents notable updates to our leaderboard—new models, new arenas, updates to the methodology, and more. Stay tuned!
For model deprecations, check the public updates on GitHub.
December 9, 2025
ernie-5.0-preview-1103 and nova-2-lite have been added to the Text leaderboard.
December 5, 2025
grok-4-fast has been renamed to grok-4-fast-chat to better reflect the specific model variant. Additionally, olmo-3-32b-think has been added to the Text leaderboard.
December 4, 2025
grok-4-fast-reasoning has been added to the Text leaderboard.
devstral-medium-2507 has been added to the new WebDev leaderboard (powered by Code Arena).
gpt-5.1-high and gpt-5.1 has been added to the Vision leaderboard.
deepseek-v3.2 and deepseek-v3.2-thinking have been added to the Text leaderboard.
seedream-4.5 has been added to the Image Edit and Text-to-Image leaderboards
December 3, 2025
gpt-5.1-search and gemini-3-pro-grounding have been added to the Search leaderboard.
December 2, 2025
mistral-large-3 has been added to the Text leaderboard.
wan2.5-t2v-preview has been added to the Text-to-Video leaderboard.
gemini-3-pro-image-preview-2k (nano-banana-pro) has been added to the Text-to-Image and Image Edit leaderboards.
December 1, 2025
KAT-Coder-Pro-V1 has been added to the new WebDev leaderboard.
flux-2-flex and flux-2-pro have been added to the Text-to-Image and Image Edit leaderboards.
November 26, 2025
claude-opus-4-5-20251101 and claude-opus-4-5-20251101-thinking-32k have been added to the Text and WebDev leaderboards
November 21, 2025
ernie-5.0-preview-1120 has been added to the Vision leaderboard.
gemini-3-pro-image-preview (nano-banana-pro) has been added to the Text-to-Image and Image Edit leaderboards.
Additionally, the following models have been added to the new WebDev leaderboard:
November 20, 2025
mercury has been added to the Text leaderboard.
November 19, 2025
cogito v2.1 has been added to the WebDev leaderboard.
gpt-5.1-high and gpt-5.1 have been added to the Text leaderboard.
November 18, 2025
gemini-3-pro has been added to the Text, Vision and WebDev leaderboards.
November 17, 2025
grok-4.1-thinking and grok-4.1 have been added to the Text leaderboard.
wan2.5-t2i-preview has been added to the Text-to-Image leaderboard.
wan2.5-i2v-preview has been added to the Image-to-Video leaderboard.
November 14, 2025
ray-3 has been added to the Text-to-Video and Image-to-Video leaderboards.
November 13, 2025
vidu-q2-turbo & vidu-q2-pro are now on the Image-to-Video leaderboard.
November 12, 2025
The WebDev leaderboard is now powered by the Code Arena experience.
amazon-nova-experimental-chat-10-20 has been added to the Text leaderboard.
November 7, 2025
ernie-5.0-preview-1022 has been added to the Text leaderboard.
reve-edit-fast has been added to the Image Edit leaderboard.
November 6, 2025
gpt-image-1-mini has been added to the Text-to-Image and Image Edit leaderboards.
November 5, 2025
Introducing Arena Expert: a new LMArena evaluation framework to identify the toughest, most expert-level prompts from real users, powering a new Expert leaderboard.
We also introduce Occupational Categories that underlie eight new leaderboards:
- Software & IT Services
- Writing, Literature, & Language
- Life, Physical, & Social Science
- Entertainment, Sports, & Media
- Business, Management, & Financial Ops
- Mathematical
- Legal & Government
- Medicine & Healthcare
Arena Expert aims to sharpen the difficulty level compared to Arena Hard. While Hard includes about a third of all LMArena prompts, Arena Expert includes only 5.5% of all prompts. Expert prompts are identified by their reasoning depth and specificity, producing sharper separations between models. By mapping all Arena prompts across occupational fields, the Occupational Categories system captures the full spectrum of real-world reasoning tasks.
→ Read more on our blog: http://news.lmarena.ai/arena-expert
November 3, 2025
MiniMax-M2 has been added to the WebDev leaderboard.
October 30, 2025
Hailuo 2.3 has been added to the Text-to-Video leaderboard.
October 28, 2025
Hailuo 2.3 has been added to the Image-to-Video leaderboard.
October 20, 2025
The following models have been added to the WebDev leaderboard:
- Claude-Haiku-4-5-20251001
- Qwen3-235b-a22b-instruct-2507
- Claude-sonnet-4-5-20250929-thinking-32k
- GLM-4.6
Additionally, Veo 3.1 variants have been added to the Text-to-Video and Image-to-Video leaderboards.
October 16, 2025
Claude Haiku 4.5 and Amazon-Nova-Experimental-Chat-10-09 have been added to the Text leaderboard.
We've also refined the logic for our Coding category to improve precision. Prompts that resembled code, but are not coding related (such as markdown) have been removed. The new rule has been applied retroactively on data, so while the Coding category is now smaller, it’s more accurate.
October 14, 2025
Sora 2 and Sora 2 Pro has been added to the Text-to-Video leaderboard.
October 13, 2025
MAI-1-Image has been added to the Text-to-Image leaderboard.
Kling 2.5 Turbo 1080p has been added to the Text-to-Video and Image-to-Video leaderboards.
October 8, 2025
DeepSeek-V3.2-Exp and the thinking variant have been added to the Text leaderboard.
October 7, 2025
Ling Flash 2.0 and Ring Flash 2.0 have been added to the Text leaderboard.
October 6, 2025
Hunyuan Vision 1.5 Thinking has been added to the Vision leaderboard.
October 4, 2025
Hunyuan Image 3.0 has been added to the Text-to-Image leaderboard.
We added a filter to remove rows where a model battles against itself. This happens very rarely, in instances where we briefly serve the same model from two different API endpoints at the same time.
October 3, 2025
Claude Sonnet 4.5 Thinking 32k and GLM 4.6 have been added to the Text leaderboard.
October 2, 2025
Claude Sonnet 4.5 has been added to the Text and Web Dev leaderboards.
October 1, 2025
Reve V1 has been added to the Image Edit leaderboard.
September 30, 2025
The following models have been added to the Text leaderboard:
- deepseek-v3.1-terminus
- deepseek-v3.1-terminus-thinking
- gemini-2.5-flash-lite-preview-09-2025
- gemini-2.5-flash-preview-09-2025
- qwen3-max-2025-09-23
- qwen3-vl-235b-a22b-instruct
- qwen3-vl-235b-a22b-thinking
September 25, 2025
New model announcement:
Seedream-4-2k has been added to the Text-to-Image and Image Edit leaderboards.
Note that Seedream-4-high-res-fal and Seedream-4-fal are variants run on the fal.ai platform. Due to differences in hosting, they are named separately as distinct models. Seedream-4-2k is the official endpoint provided by ByteDance.
September 19, 2025
New model announcements:
Grok-4-fast has been added to the Text leaderboard.
Grok-4-fast-search has been added to the Search leaderboard.
September 18, 2025
We have added a new "preliminary" tag to the leaderboard. If a model is tested anonymously and is subsequently released publicly, we mark its score as "preliminary" until enough fresh votes have been collected after the model’s public release. The tag indicates that scores may shift as community prompts and votes evolve after public launch. See our leaderboard policy for more details about evaluating models.
September 17, 2025
New model announcements:
Longcat-Flash-Chat, Qwen 3 Next-80b-a3b-instruct and Qwen 3 Next-80b-a3b-thinking have been added to the Text leaderboards.
We've updated our data pipeline to add a filter which removes votes from users who exhibit statistically anomalous voting patterns. This improves the quality of the rankings by removing votes from users whose votes are arbitrary, rather than based on the quality of the responses.
September 16, 2025
New model announcement:
Seedream 4 High Res has been added to the Text-to-Image and Image Edit leaderboards.
Deepseek v3.1 & Deepseek v3.1-thinking have been added to the WebDev leaderboard.
September 12, 2025
New model announcement:
Seedream 4 has been added to the Text-to-Image and Image Edit leaderboards.
September 8, 2025
New model announcements:
Qwen3-max-preview and Kimi-K2-0905-preview have been added to the Text Leaderboard.
We also enabled filtering for the mistaken image generation and image edit requests for text arena.
September 2, 2025
Due to the increase in image generation traffic brought by nano-banana, we noticed there were prompts in our vision arena data which were asking for image generation but did not have image output enabled. We've implemented an LLM based rule to filter these rows out from the vision leaderboard calculation.
August 29, 2025
New model announcements:
Diffbot-small-xl has been added to the Search Leaderboard
Qwen-3-Image-Prompt-Extend has been added to the Text-to-Image Leaderboard.
The following have been added to the Text Leaderboard:
- DeepSeek V3.1 (thinking and non-thinking)
- Hunyuan-t1-20250711
August 28, 2025
New model announcement: MAI-1-preview has been added to the Text Leaderboard.
August 26, 2025
New model announcement: Gemini-2.5-Flash-Image-Preview ("nano-banana") has been added to the Text-to-Image and Image Edit leaderboards.
GPT-5 and Claude Opus 4.1 have been added to the Search Leaderboard.
We also noticed that the effects of response style are different for search than they are for ordinary chat so we'll be defaulting this leaderboard to ordinary Bradley-Terry while we study search specific style effects.
August 22, 2025
New model announcements
The following have been added to the Text and Vision leaderboards:
Lucid Origin has been added to the Text-to-Image leaderboard.
Ray 2 has been added to the Text-to-Video and Image-to-Video leaderboards
Runway Gen 4 Turbo has been added to the Image-to-Video leaderboard
August 20, 2025
New model announcement: Qwen-Image-Edit has been added to the Image Edit leaderboard.
August 18, 2025
New model announcement: Claude Opus 4.1 Thinking as been added to the Text and WebDev Arena leaderboards. Sora has been added to the Text-to-Image leaderboard.
August 15, 2025
New model announcement: three additional gpt-5 models are on the Text Leaderboard. These three reasoning models were configured with the highest reasoning setting.
August 13, 2025
New model announcement: gpt-0ss-120b and gpt-oss-20b have been added to the Text and WebDev leaderboards. Hailuo 2 Pro versions have been added to the Text-to-Video and Image-to-Video leaderboards.
August 11, 2025
New model announcement: Claude Opus 4.1 is on Text and WebDev leaderboards.
August 7, 2025
New model announcement: GPT-5 is on the Text, WebDev, and Vision leaderboards.
August 6, 2025
Big update: three new leaderboards!
Check out the Search, Text-to-Video, and Image-to-Video leaderboards.
Since the video arenas are used through our discord server, there are a few considerations we made for handling the votes. Currently, the model identities are revealed after two votes are cast on a generation. For fairness, we only use the votes cast before the model names are revealed when constructing the leaderboard.
The video arenas are also the first arenas where multiple votes can be cast on the same pair of generations, so unlike the other arenas, some votes are cast by people other than the author of the prompt. The overall leaderboard is computed using all anonymous votes, and we've created a new category which uses only the votes cast by the prompt's author.
August 5, 2025
We have updated the "total votes" counts to include battles involving models not included on the leaderboard (for example, due to being deprecated). The battles between these models and models present on the leaderboard are informative of model strengths, even if the former are not shown, and thus help reduce the variance of the scores. The leaderboard computation is not changing; you will only see a change in the vote counts.
August 4, 2025
New model announcements: GLM-4.5 and GLM-4.5 Air are now on the Text leaderboard.
August 1, 2025
New model announcement: Qwen3-235b-a22b-instruct-2507 is now on the Text leaderboard.
July 28, 2025
New model announcements: Qwen3-Coder and Kimi K2 are now on the WebDev leaderboard.
July 25, 2025
New model announcements! Imagen 4 Generate Preview 06-06 v2 and Imagen 4 Ultra Generate Preview 06-06 v2 are now on the Text-to-Image leaderboard.
July 23, 2025
We made improvements to the methodology behind Arena scores!
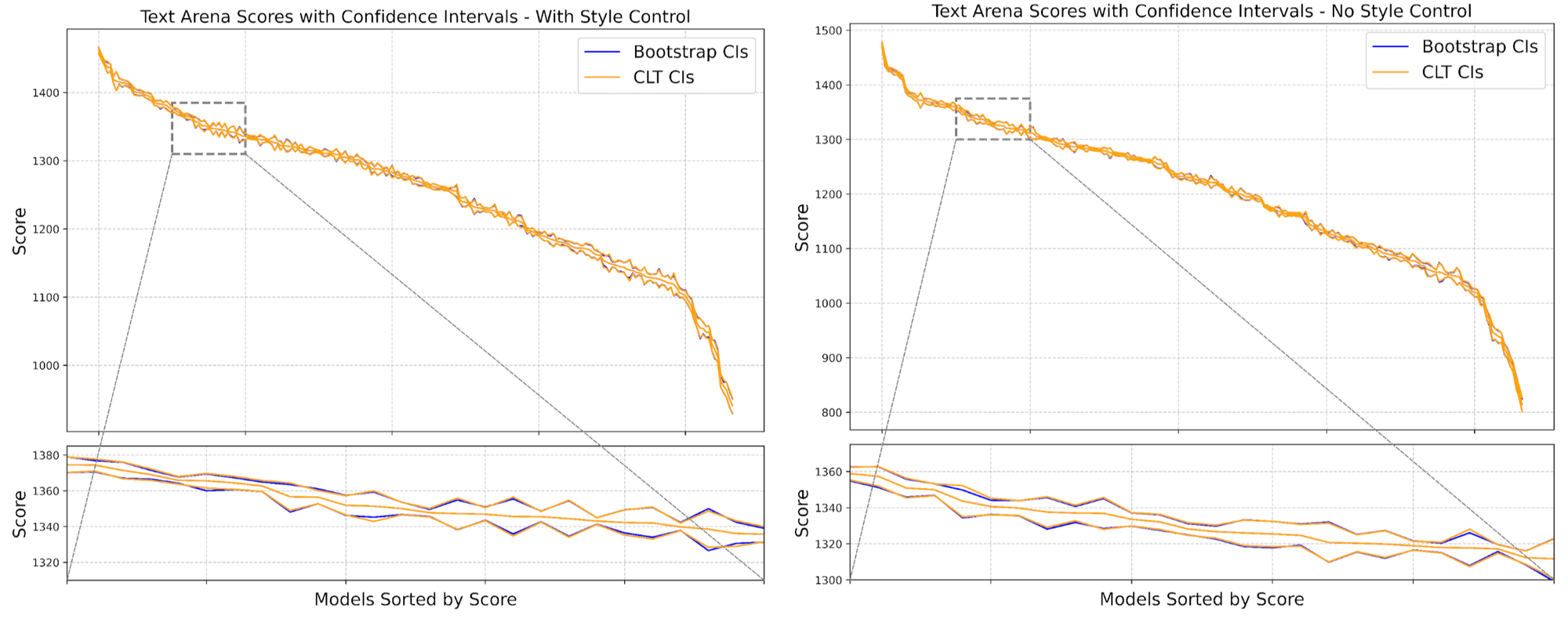
Our leaderboard uses confidence intervals to represent the uncertainty and variability inherent in estimating scores based on human voting. Up until now, our confidence intervals have been computed via bootstrapping, a process where we resample the dataset many times, calculate scores on each, and then look at the distribution of the scores over all the runs. While statistically sound, this is computationally intensive, especially with a large number of battles. We’ve recently moved to a new method based on the Central Limit Theorem (CLT) for M-estimators, which allows us to compute confidence intervals via a closed form equation.
We validated this approach by comparing the confidence intervals computed via bootstrapping, with those using the CLT and confirmed that the results are in very close parity (with a fraction of the compute cost and time!). See below:
On LMArena, every vote counts towards producing the leaderboard, but what happens when some models appear more than others? When new models are released, they inevitably have fewer votes than those which have been in use for a while, and when models are deprecated it becomes impossible to collect more votes for them.
To counteract this imbalance and produce a leaderboard that is fair and equally representative of all models, we use an improved reweighting scheme that reweights battles inversely proportionally to how frequently they appear.
The CLT confidence intervals above take these weights into account. Reweighting increases the variance of Arena scores, and we observe wider confidence intervals as a result. This mean that the new rankings will have more ties due to overlapping confidence intervals, especially when there are fewer votes per model like in the vision arena.
July 17, 2025
New model announcements! Kimi K2 is on the Text leaderboard, Seededit 3 is on the Image Edit leaderboard, and Grok 4 is on the Vision leaderboard.
July 15, 2025
We're announcing four new models! Grok 4 is on the Text and WebDev leaderboards, Claude Opus 4 Thinking is on the Text leaderboard, Claude Sonnet 4 Thinking is on the Text leaderboard, and Seedream 3 is on the Text-to-Image leaderboard.
July 14, 2025
We made improvements to our data processing—in particular, we strengthened our deduplication and identity leak detection pipelines.
Deduplication aims to reduce the impact of over-represented or repetitive conversations using a hash-based approach. We count how many times each unique prompt appears. Prompts in the top 0.5% percentile are considered high-frequency. For these high-frequency prompts, we keep only a limited number of samples and discard the rest. Deduplication filters out around 10% of all submitted votes.
Identity leak detection filters out user prompts whose intent is to reveal model information. We first use an LLM classifier to label conversations as identity_leak if they include user prompts that directly attempt to extract or expose model details (e.g., "What is your name?"). We filter out conversations labeled as identity_leak, as well as associated conversations. Less than 4% of all votes are labeled as identity_leak.
We're excited to continue iterating and improving our data processing pipeline!