Studying the Frontier: Arena Expert Arena Expert is a great way to differentiate between frontier models. In this analysis, we compare how models perform on 'general' vs 'expert' prompts, focusing on 'thinking' vs 'non-thinking' models.
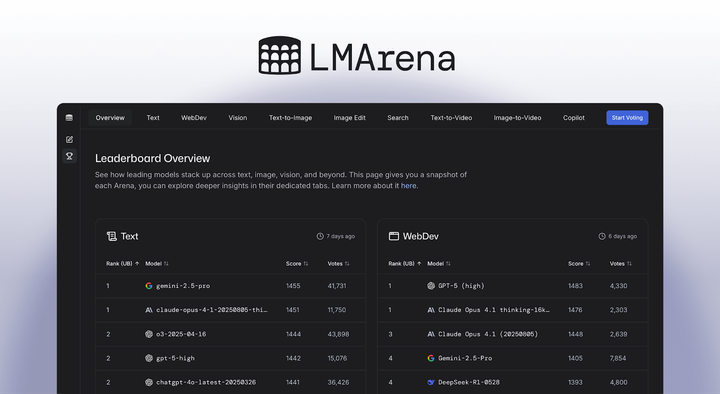
LMArena's Ranking Method Since launching the platform, developing a rigorous and scientifically grounded evaluation methodology has been central to our mission. A key component of this effort is providing proper statistical uncertainty quantification for model scores and rankings. To that end, we have always reported confidence intervals alongside Arena scores and surfaced any
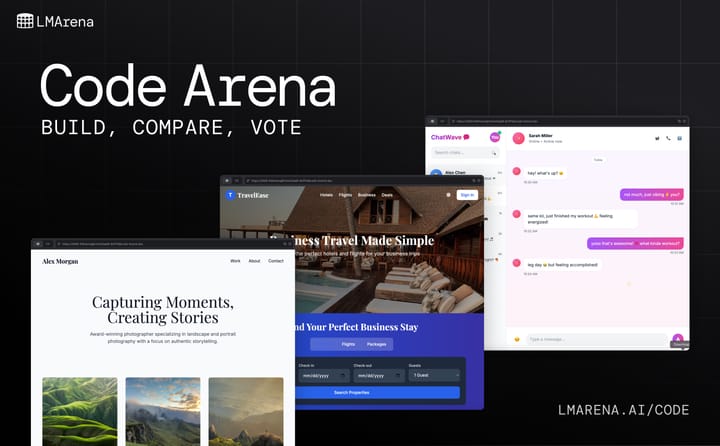
The Next Stage of AI Coding Evaluation Is Here Introducing Code Arena: live evals for agentic coding in the real world AI coding models have evolved fast. Today’s systems don’t just output static code in one shot. They build. They scaffold full web apps and sites, refactor complex systems, and debug themselves in real time. Many now
Arena Expert and Occupational Categories The next frontier of large language model (LLM) evaluation lies in understanding how models perform when challenged by expert-level problems, drawn from real work, across diverse disciplines.
Re-introducing Vision Arena Categories Since we first introduced categories over two years ago, and Vision Arena last year, the AI evaluation landscape has evolved. New categories have been added, existing ones have been updated, and the leaderboards they power are becoming more insightful with each round of community input.
New Product: AI Evaluations Today, we’re introducing a commercial product: AI Evaluations. This service offers enterprises, model labs, and developers comprehensive evaluation services grounded in real-world human feedback, showing how models actually perform in practice.
Nano Banana (Gemini 2.5 Flash Image): Try it on LMArena “Nano-Banana” is the codename that was used on LMArena during testing for what is now known as: Gemini 2.5 Flash Image. Try it for yourself directly on LMArena.ai
Introducing BiomedArena.AI: Evaluating LLMs for Biomedical Discovery LMArena is honored to partner with the team at DataTecnica to advance the expansion of BiomedArena.ai: a new domain-specific evaluation track.
A Deep Dive into Recent Arena Data Today, we're excited to release a new dataset of recent battles from LMArena! The dataset contains 140k conversations from the text arena.
Search Arena & What We’re Learning About Human Preference Search Arena on LMArena goes live today, read more about what we've learned so far about human preference with the search-augmented data.
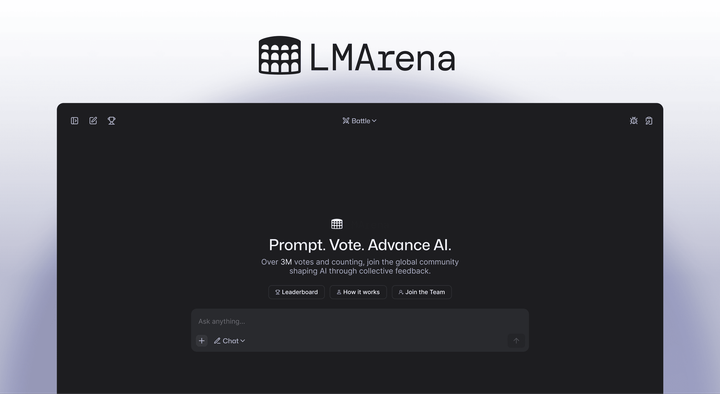
Hello from LMArena: The Community Platform for Exploring Frontier AI At LMArena, everything starts with the community. There have been a lot of new members joining us in the past few months so we thought it would be a good time to reintroduce ourselves! Created by researchers from UC Berkeley’s SkyLab, LMArena is an open platform where everyone can
LMArena and The Future of AI Reliability About a month ago, we announced that LMArena was becoming a company to better support our growing community platform. As we take this next step, we're staying true to our original mission of rigorous, neutral, and community-driven evaluations. Today, we’re excited to share that we’ve raised
Celebrating Community Impact: 3M+ votes, 400+ models, and 300+ pre-release tests To date, the community has evaluated over 400+ public models on LMArena as well as 300+ pre-release tests. Tens of millions of battle pairings have been served to users across the world, and each vote has shaped real-world AI performance and development. Around this time two years ago, the community
Does Sentiment Matter Too? Introducing Sentiment Control: Disentangling Sentiment and Substance Contributors: Connor Chen Wei-Lin Chiang Tianle Li Anastasios Angelopoulos Introduction You may have noticed that recent models on Chatbot Arena appear more emotionally expressive than their predecessors. But does this added sentiment actually improve their rankings on the leaderboard? Our previous exploration revealed