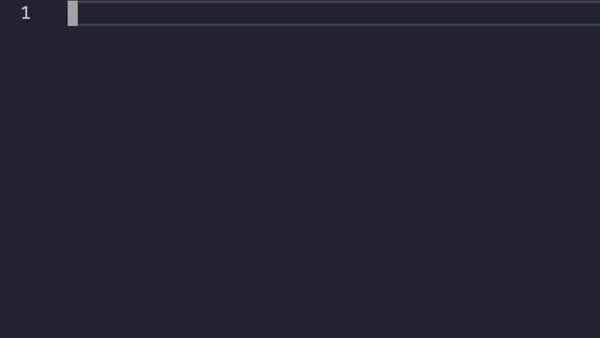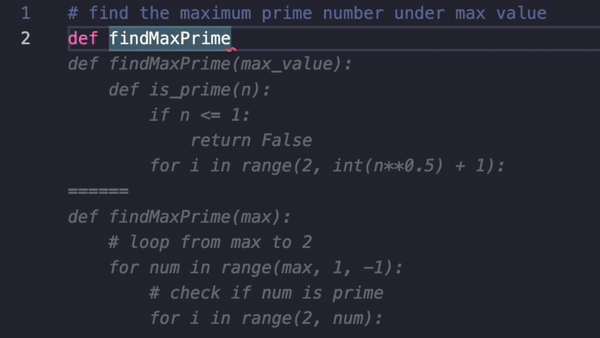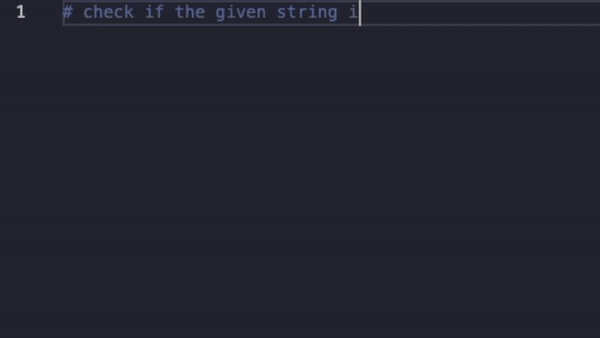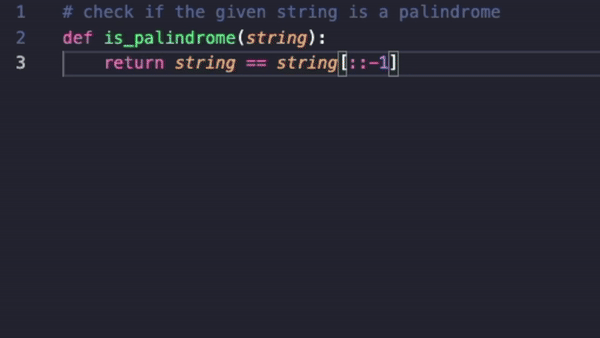
WebDev Arena: A Live LLM Leaderboard for Web App Development WebDev Arena allows users to test LLMs in a real-world coding task: building interactive web applications.
RepoChat Arena RepoChat lets models automatically retrieve relevant files from the given GitHub repository. It can resolve issues, review PRs, implement code, as well as answer higher level questions about the repositories-all without requiring users to provide extensive context.
Arena Explorer We developed a topic modeling pipeline and the Arena Explorer. This pipeline organizes user prompts into distinct topics, structuring the text data hierarchically to enable intuitive analysis. We believe this tool for hierarchical topic modeling can be valuable to anyone analyzing complex text data.
Code Editing in Copilot Arena Copilot Arena enables not only paired code completions but also paired code edits as well. Unlike code completions—which automatically appear after short pauses—code edits are manually triggered by highlighting a code snippet and then writing a short task description.
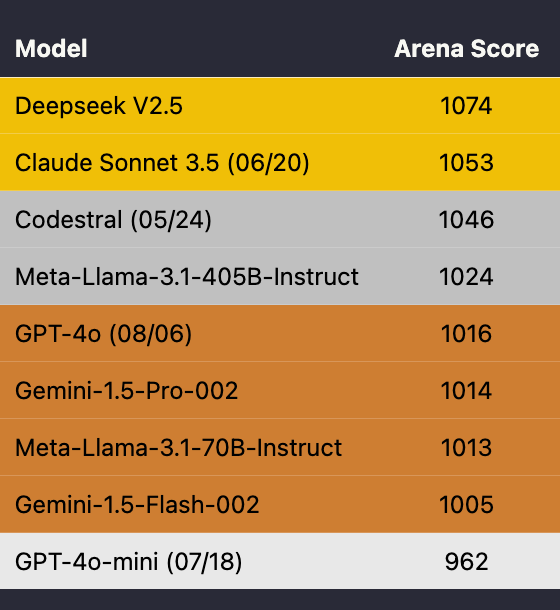
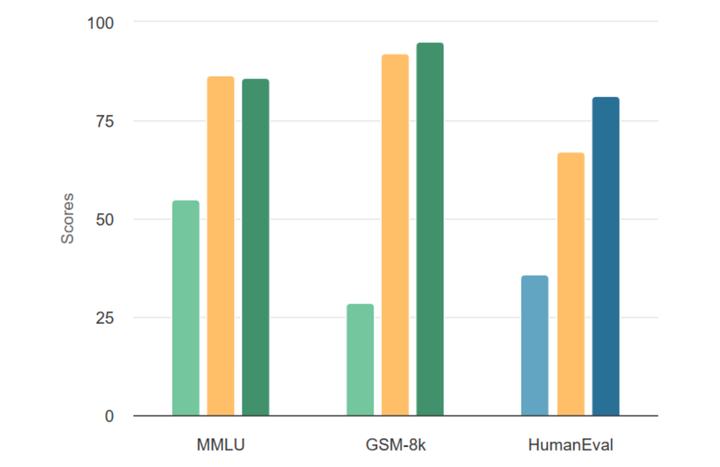
Catch me if you can! How to beat GPT-4 with a 13B model Authors Shuo Yang* Wei-Lin Chiang* Lianmin Zheng* Joseph E. Gonzalez Ion Stoica Announcing Llama-rephraser: 13B models reaching GPT-4 performance in major benchmarks (MMLU/GSK-8K/HumanEval)! To ensure result validity, we followed OpenAI’s decontamination method and found no evidence of data contamination. What’s the trick behind it? Well, rephrasing
Copilot Arena Copilot Arena has been downloaded 2.5K times on the VSCode Marketplace, served over 100K completions, and accumulated over 10K code completion battles.
Chatbot Arena Categories By grouping tasks into categories, we can assess models’ strengths and weaknesses in a more granular way.