
Re-introducing Vision Arena Categories
Since we first introduced categories over two years ago, and Vision Arena last year, the AI evaluation landscape has evolved. New categories have been added, existing ones have been updated, and the leaderboards they power are becoming more insightful with each round of community input.

Since we first introduced categories over two years ago, and Vision Arena last year, the AI evaluation landscape has evolved. New categories have been added, existing ones have been updated, and the leaderboards they power are becoming more insightful with each round of community input.
If you need a refresher: categories are how we organize conversations on LMArena. Each message can be tagged into one or more categories, though tagging isn’t required. This flexibility ensures that we capture the richness of real-world use cases without forcing conversations into boxes.
When you view a category leaderboard, you’re seeing the same ranking methodology as the overall Arena leaderboard, but filtered only to conversations within that category. This makes categories a powerful way to zoom in on specific domains of model performance, whether that’s coding, creative writing, or multimodal reasoning.
In Vision Arena, users upload images and give text prompts asking all sorts of questions, from homework to storytelling. Like in Text Arena, many insights can be gained by looking at the categories of these conversations, both in terms of the prompts and the accompanying images.
Today, we’ll define and explain the new Vision Arena categories paired with example prompts and images.
Captioning
The Captioning category covers requests for general descriptions of images. This measures a model’s capacity to understand and describe images, often for users interested in getting overall information about an image, rather than seeking specific information from it.


Creative Writing
The Creative Writing category is designed to capture the models’ skills in compositions outside of academic, professional, and technical areas, and typically involve creativity, imagination or storytelling.


Diagrams
For testing recognition and understanding of technical information in images, we have the Diagrams category. This includes instances where the image contains graphs, charts, or figures, and the user is asking questions which require understanding of the concepts of the visuals.
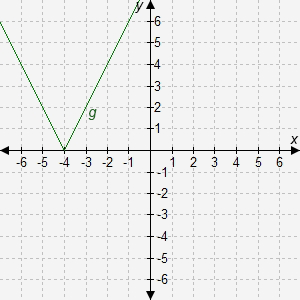
Entity Recognition
For recognizing, identifying, and explaining specific objects, items, or people from images, we have the Entity Recognition category. This tests the models on their ability to associate visual features of particular things with the associated knowledge from their pretraining.


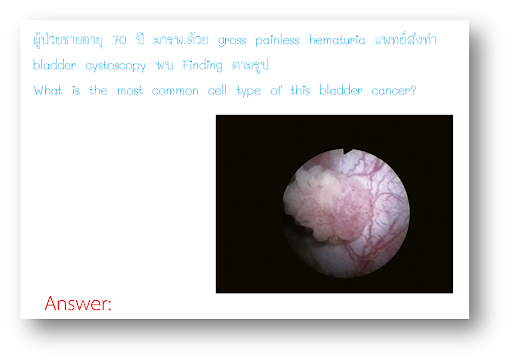
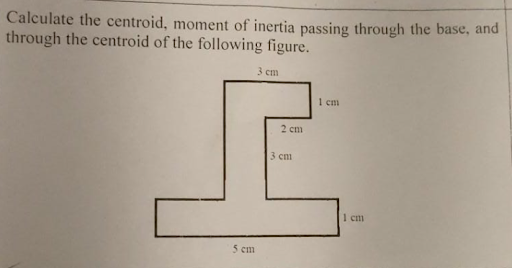
Homework
This category measures models’ abilities to understand and solve problems from assignments based on pictures of the assignments. These vary widely in topics and across the level of education.
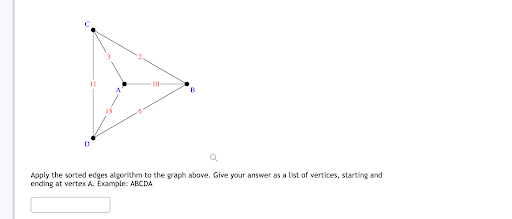
Humor
The Humor category is a lighthearted and fun category which contains images and prompts where users ask the models to identify funny components or explain the joke. Understanding and explaining humor has historically been a difficult task for AI, and adding image understanding makes it even more challenging.

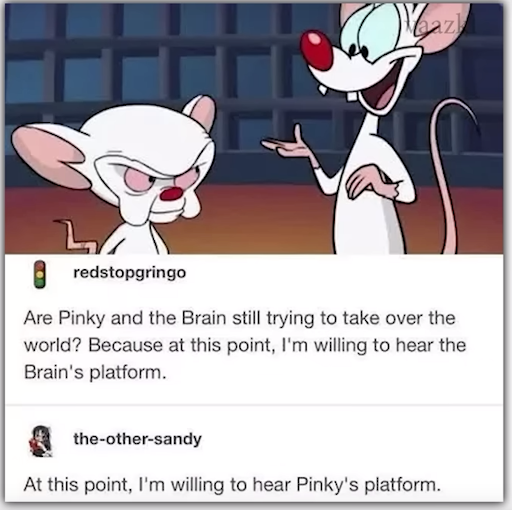
Optical Character Recognition (OCR)
The OCR category contains images with text, with prompts asking questions for information from the textual components of the image. This is the test of the models’ abilities to read and understand text in images.


Conclusion
These examples highlight the variety of inputs and tasks that people are using Vision Arena’s multimodal capabilities for, while also providing context for the categories.
You can now explore how your favorite AI models compare across these different categories on the Vision Leaderboard!


