
RepoChat Arena
RepoChat lets models automatically retrieve relevant files from the given GitHub repository. It can resolve issues, review PRs, implement code, as well as answer higher level questions about the repositories-all without requiring users to provide extensive context.

A Live Benchmark for AI Software Engineers
Contributors:
Yifan Song
Naman Jain
Manish Shetty
Wei-Lin Chiang
Valerie Chen
Wayne Chi
Anastasios N. Angelopoulos
Ion Stoica
Introduction
An integral part of using LLMs as part of a user’s coding workflow is navigating and understanding complex code bases. We launched RepoChat – a new arena that answers code-related queries using a user-provided github repository link.
RepoChat lets models automatically retrieve relevant files from the given GitHub repository. It can resolve issues, review PRs, implement code, as well as answer higher level questions about the repositories-all without requiring users to provide extensive context.
Video 1. A demo of RepoChat.
So far, RepoChat has collected around 20k battles and over 4k votes. All statistics calculated in this blog use conversations and votes collected between November 30, 2024 to Feburary 11, 2025 inclusive.
^ Table 1. Number of conversations, votes, and unique GitHub links logged from 11/30/2024 - 02/11/2025.
In this blog we will cover:
- Initial Results: our preliminary results for the RepoChat leaderboards
- How do people use RepoChat: an analysis of the distribution of github links and user queries’ category, length, language, etc.
- How does it work: a more technical and detailed explanation of the RepoChat pipeline and implementation
- Further Analysis and Results: retriever and style controlled leaderboards, and other analysis of model rankings.
Initial Leaderboards
Since there are two separate components (retriever and answer), we produce two separate leaderboards. Jump to this section for details about how the leaderboards are calculated, and to further analysis for more leaderboards such as style-control. All leaderboards can be reproduced using our google colab notebook.
^ Table 2. Arena ratings of seven popular models based on over 4K votes collected between November 30, 2024 to Feburary 11, 2025. This ranks the models for generating model response
^ Table 3. Arena ratings of the two retrievers based on 4K votes collected between November 30, 2024 to Feburary 11, 2025. This ranks the models for retrieving relevant files.
How do people use RepoChat?
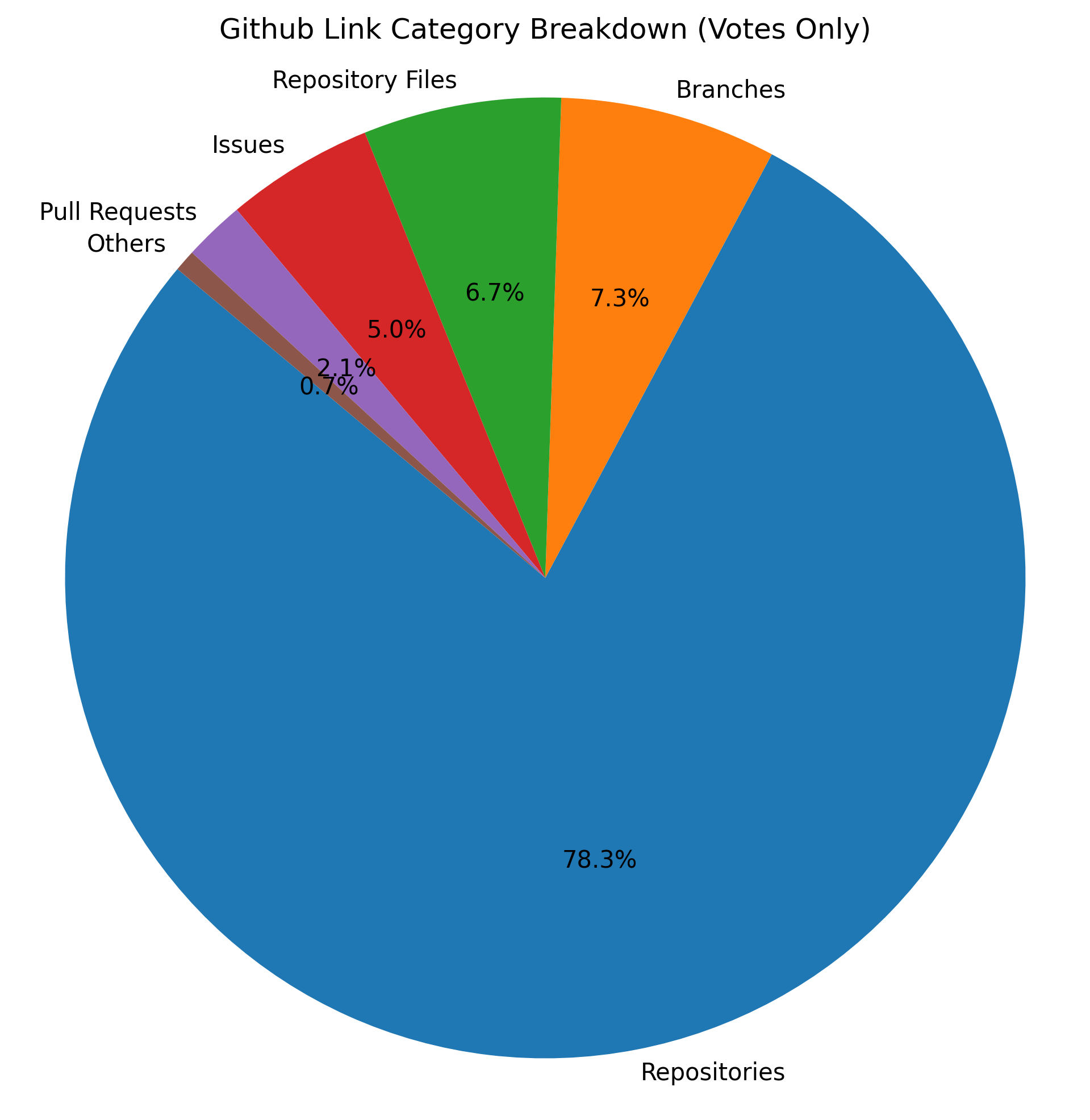
What types of Github links do users input? RepoChat features a wide range of GitHub links, including repositories, issues, pull requests, and others. We find that the vast majority (almost 80%) of user input links are repository links, followed by issues and branches.
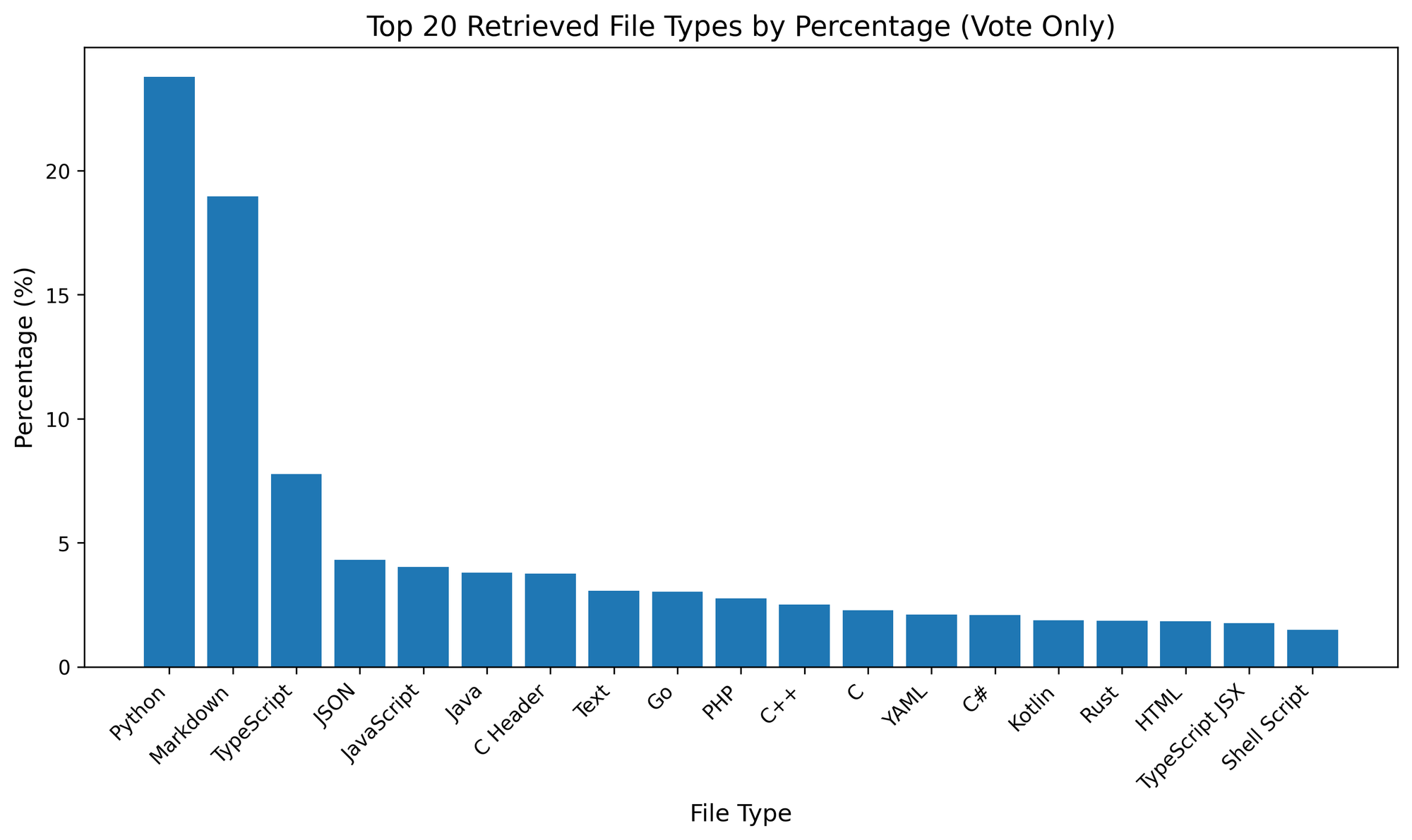
What programming languages do people ask about? The following statistic is calculated based on the file extensions of the relevant files. This serves as an indicator of the programming languages users are most frequently inquiring about/coding in. The abundance of markdown files is primarily due to README files, which are often extracted due to containing critical descriptions and instructions for the repository.
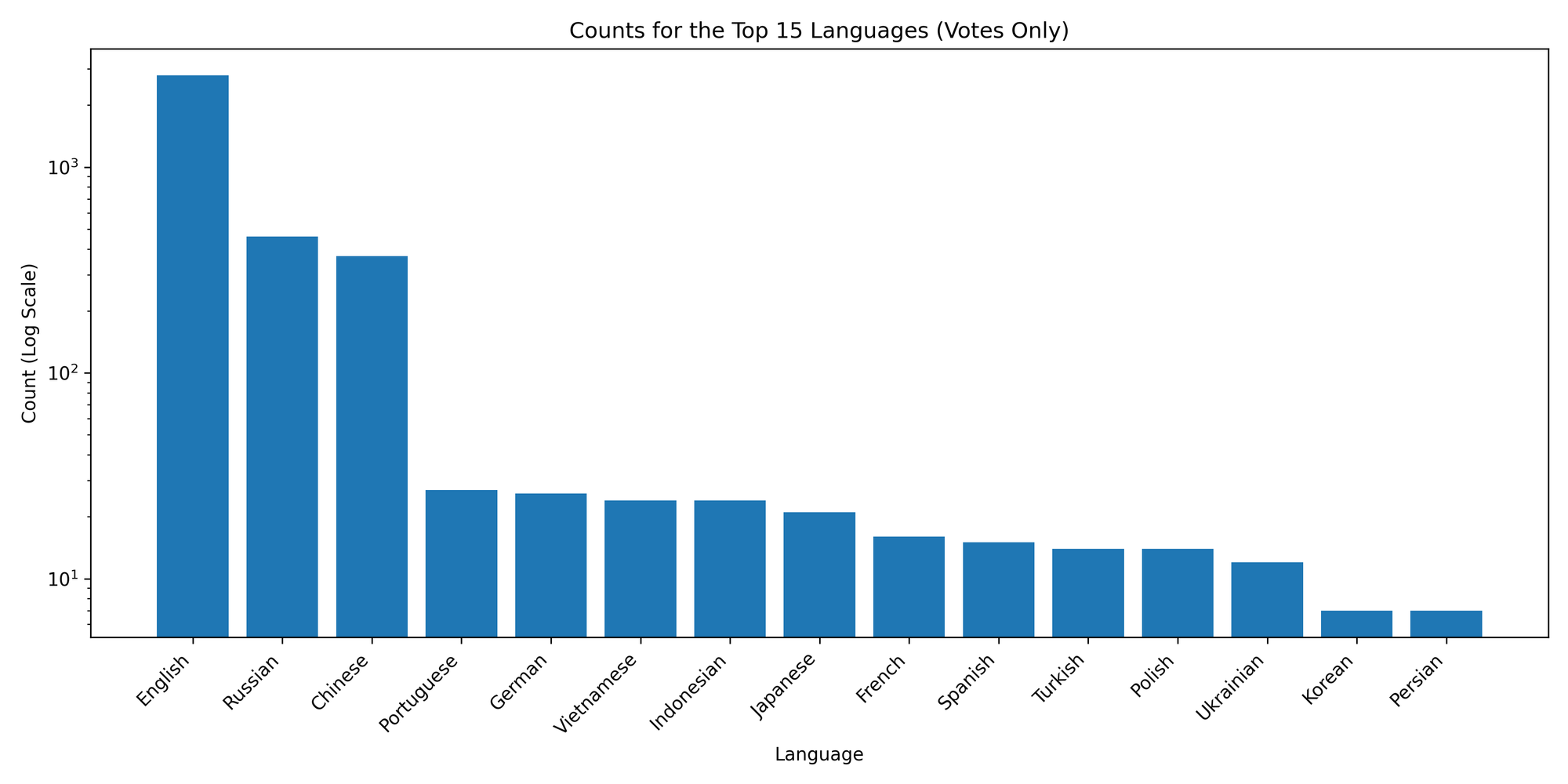
What natural languages do the user queries contain? Most of our votes contain user queries in English, followed by Russian and Chinese.
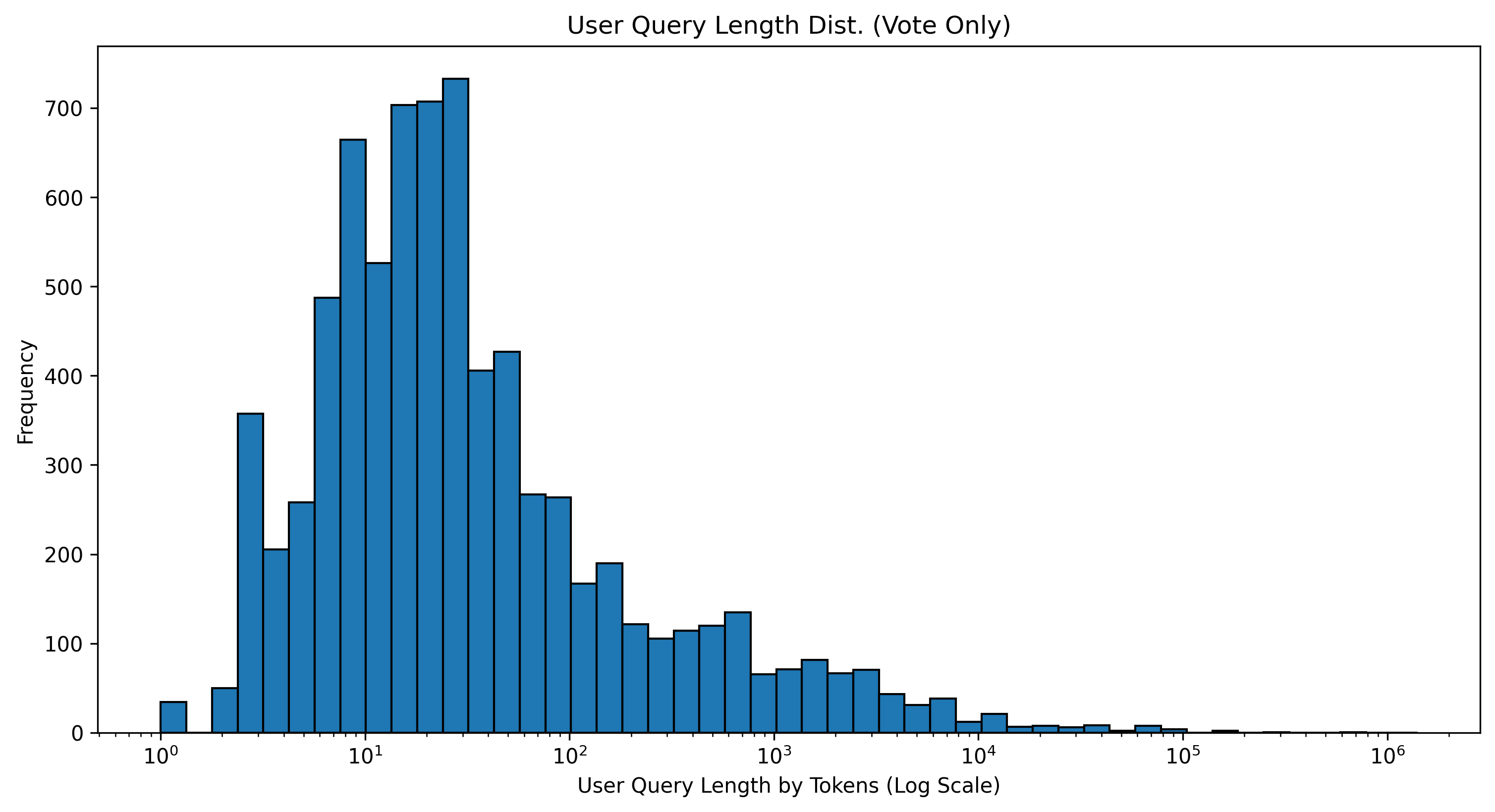
How long are the user queries? The user query length varies significantly, ranging from a minimum of 1 token to a maximum of 1,406,325 tokens, with a median of 22 tokens. Short-length queries mostly consist of prose requesting implementations or instructions, whereas longer queries often include extensive code blocks.
How long are the retrieved file contexts? The distribution of retrieved file content is more stable, with a median of 8,870, an average of 12,508, and a maximum of 126,329 tokens, with the occasional empty retrieval.
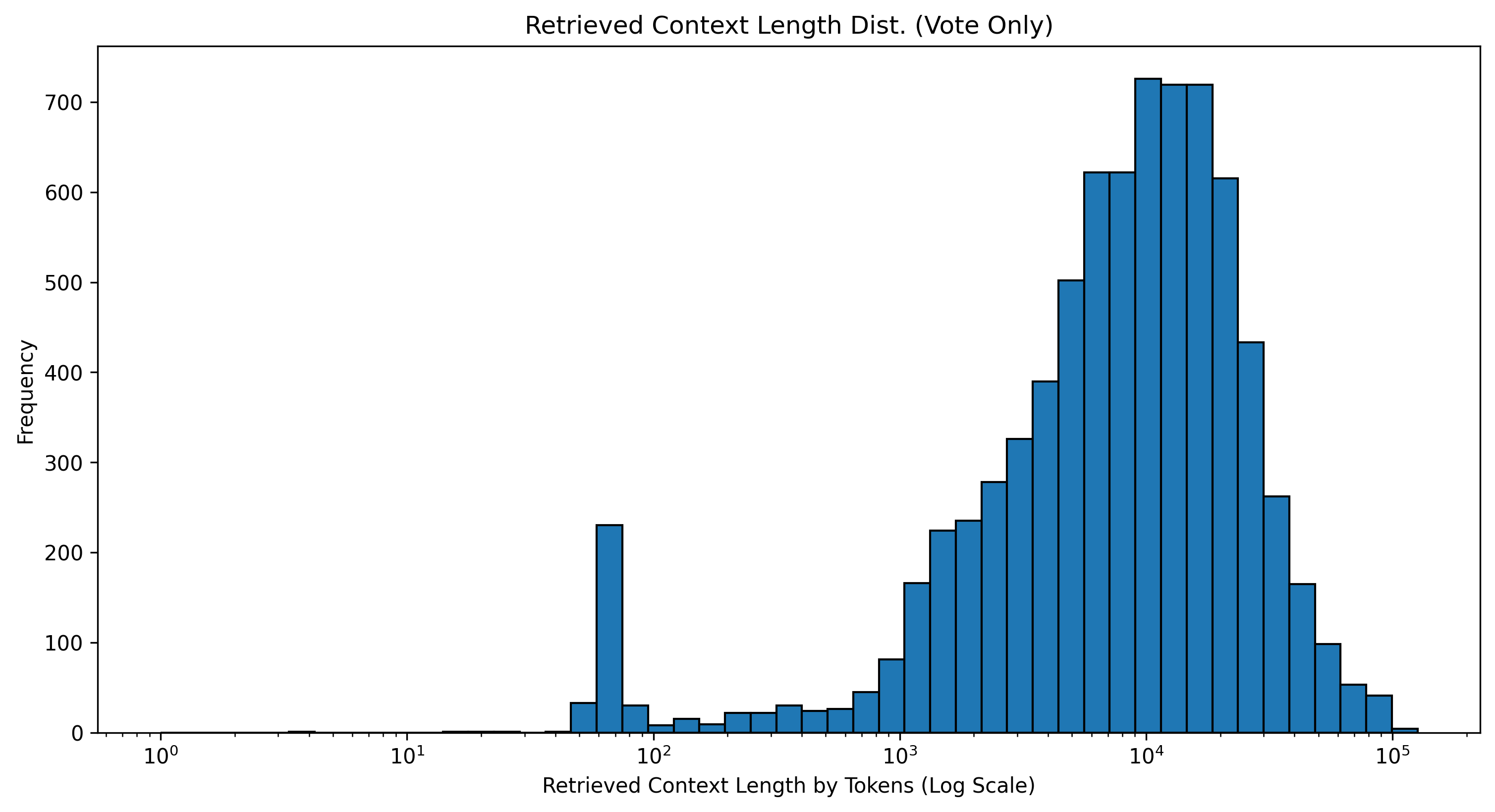
- What are the most common user query types?
- For more examples, please refer to the appendix. We have also released a dataset of around 4k battles here on Hugging Face.
- High level questions about a repository:
- https://github.com/Mrjoulin/ITMOLabs
“What is this repository about? How I can use it? What main languages and frameworks are used here?”
- https://github.com/Mrjoulin/ITMOLabs
- Specific how-to questions:
- https://github.com/notfiz/de3u
“How do I install this on Linux (Mint 22)? Be thorough.”
- https://github.com/notfiz/de3u
- Implementation requests:
- https://github.com/dipu-bd/lightnovel-crawler
“Write a Python script that fetches the top 10 highest-rated light novels from Anilist and then downloads all of their volumes in .epub format using this.”
- https://github.com/dipu-bd/lightnovel-crawler
- Specific explanation requests:
- https://github.com/hhy-huang/GraphJudger
“How is the graph knowledge graph in this repository generated?”
- https://github.com/hhy-huang/GraphJudger
- Requests for solving an issue:
- https://github.com/rust-lang/rfcs/issues/1856
“In 100 words or less, what is the easiest approach to resolving this issue (without giving up)?”
- https://github.com/rust-lang/rfcs/issues/1856
- Requests for reviewing a PR:
- https://github.com/pandas-dev/pandas/pull/56061
“Explain the optimization.”
- https://github.com/pandas-dev/pandas/pull/56061
- Queries with code snippets, requests for modifying existing code, and debugging: (click the arrow to expand the full query)

debug the code as a professional would do. The code is for running in jupyter.
import pandas as pd
import numpy as np
from sktime.forecasting.model_selection import (
ForecastingOptunaSearchCV,
ExpandingWindowSplitter,
temporal_train_test_split
)
from sktime.forecasting.base import ForecastingHorizon
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.forecasting.statsforecast import (
StatsForecastMSTL,
StatsForecastAutoETS,
StatsForecastAutoARIMA,
StatsForecastAutoTheta
)
from sktime.transformations.series.detrend import Detrender
from sktime.transformations.series.deseasonalize import Deseasonalizer
import optuna
import warnings
warnings.filterwarnings('ignore')
# Load your time series data
# Ensure 'pivot_table' is defined and contains the 'PAN4_PIBPMG4' series
y = pivot_table['PAN4_PIBPMG4']
# Split the data into train and test sets
y_train, y_test = temporal_train_test_split(y, test_size=8)
# Define the forecasting horizon
fh = ForecastingHorizon(np.arange(1, 9), is_relative=True)
# Set up cross-validation with an expanding window splitter
cv = ExpandingWindowSplitter(fh=fh, initial_window=len(y_train) - 8)
# Define the parameter space for tuning
param_distributions = {
'forecaster**season_length': optuna.distributions.CategoricalDistribution([(4,), (8,)]),
'forecaster**trend_forecaster': optuna.distributions.CategoricalDistribution([
StatsForecastAutoETS(model="ZZZ"),
StatsForecastAutoARIMA(seasonal=True),
StatsForecastAutoTheta()
]),
'forecaster\_\_stl_kwargs': {
'robust': optuna.distributions.CategoricalDistribution([True, False]),
'period': optuna.distributions.IntUniformDistribution(4, 8)
}
}
# Initialize the MSTL forecaster
mstl_forecaster = StatsForecastMSTL()
# Create a pipeline with optional transformations
forecaster = TransformedTargetForecaster(steps=[
("detrender", Detrender()),
("deseasonalizer", Deseasonalizer()),
("mstl_forecaster", mstl_forecaster)
])
# Set up the OptunaSearchCV
optuna_search = ForecastingOptunaSearchCV(
forecaster=forecaster,
cv=cv,
param_distributions=param_distributions,
scoring=MeanAbsolutePercentageError(symmetric=True),
n_trials=100,
random_state=42
)
# Fit the model
optuna_search.fit(y_train)
# Predict
y_pred = optuna_search.predict(fh)
# Evaluate
mape = MeanAbsolutePercentageError(symmetric=True)
final_mape = mape(y_test, y_pred)
print(f"Final sMAPE: {final_mape:.2f}")
# Plot results
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 7))
plt.plot(y_train.index, y_train.values, label='Training Data', color='blue')
plt.plot(y_test.index, y_test.values, label='Test Data', color='green')
plt.plot(y_pred.index, y_pred.values, label='Predictions', color='red', linestyle='--')
plt.title('MSTL Forecast Results with Optuna Optimization')
plt.legend()
plt.grid(True)
plt.show()
# Save the best model
from joblib import dump
dump(optuna*search.best_forecaster*, 'best_mstl_model_optuna.joblib')
print("\nBest model saved as 'best_mstl_model_optuna.joblib'")
# Print additional optimization results
print("\nOptimization Results:")
print("="\*50)
print(f"Number of completed trials: {len(optuna*search.cv_results*)}")
print(f"Best trial number: {optuna*search.best_index*}")
print(f"Best sMAPE achieved during optimization: {optuna*search.best_score*:.2f}")
# Print best parameters
print("\nBest Parameters Found:")
print("="\*50)
for param, value in optuna*search.best_params*.items():
print(f"{param}: {value}")
How Does It Work?
Each generated answer is the collaborative effort between two separate LLM models. The retriever model extracts the relevant files from the github repository according to the given user input. The extracted file contents are then concatenated together with the user query and used as a prompt for the answer model, which then generates the response.
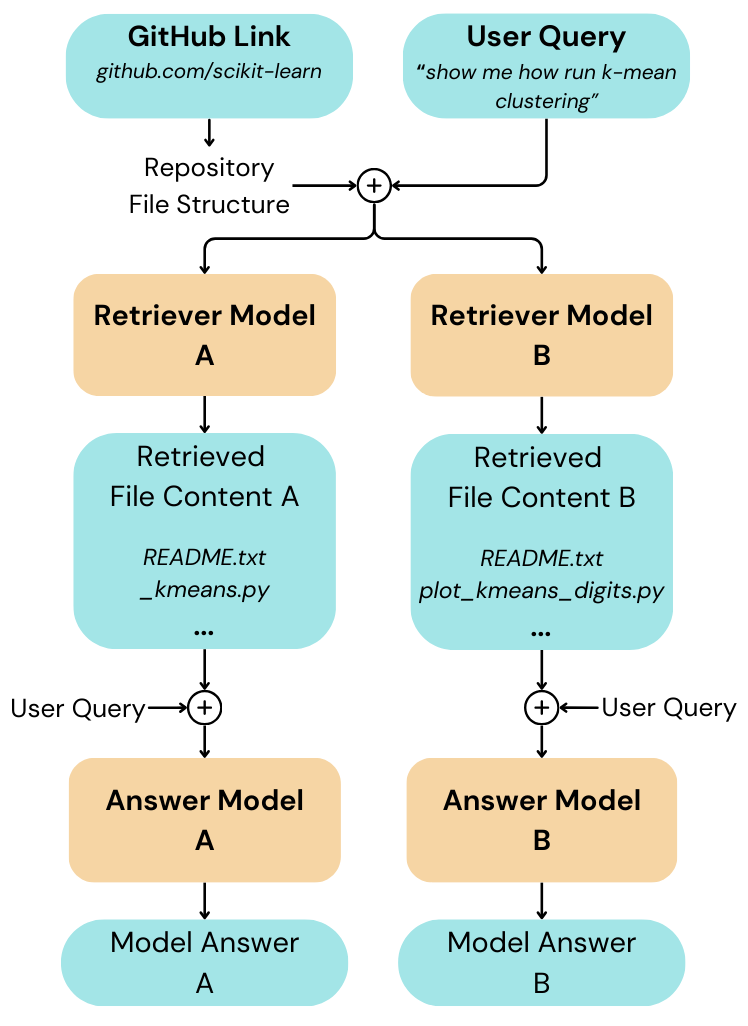
File Retrieval
We select two models as retrievers: gemini-1.5-flash-002 and gpt-4o-mini.
When a valid GitHub link is provided, the repository is cloned, and its file structure is extracted and formatted in an indented layout. The retriever model is then prompted to strategically identify files from the file structure that are potentially useful for answering the query. It then outputs these files in decreasing order of relevance and a specified markdown format.
Click to review retriever prompt
The following files are found in the repository:
{file structure}
Please provide a list of files that you would like to search for answering the user query.
Enclose the file paths in a list in a markdown code block as shown below:
```
1. [[ filepath_1 ]]\n
2. [[ filepath_2 ]]\n
3. [[ filepath_3 ]]\n
...
```
Think step-by-step and strategically reason about the files you choose to maximize the chances of finding the answer to the query. Only pick the files that are most likely to contain the information you are looking for in decreasing order of relevance. Once you have selected the files, please submit your response in the appropriate format mentioned above (markdown numbered list in a markdown code block). The filepath within [[ and ]] should contain the complete path of the file in the repository.
{query}
Model Response Generation
The contents of relevant files are extracted, concatenated with the user query, and provided to the responding LLM as a prompt in a specified format. If the provided link is not a direct repository link but instead links to issues or pull requests, a query context section containing the content of the issue or PR thread is also included.
Click to view answer model prompt format
Here is a list of files in the repository that may help you answer the query:
{pairs of (file_name, file_content)}
___
[INSTRUCTION]
You are an expert software engineer. Answer the following user query using provided context retrieved from the {repository_name} repository.
[QUERT CONTEXT]
{issue/PR content}
[USER QUERY]
{user query}
Further Analysis and Results
Style Control
Style (length and Markdown formatting) significantly impacts model ranking. A better formatted or visually appealing answer, though not necessarily better, is more likely to win. The style-controlled leaderboard isolates writing style from content quality. For details on our methodology, refer to this blog post.
^ Table 4. Style-controlled arena ratings of the answer models.
Claude 3.5 Sonnet’s score and ranking has improved significantly with style control, claiming the top spot. GPT-4o’s score has decreased, greatly narrowing its lead over other models. Gemini 1.5 Pro has also seen a notable boost in score, climbing one rank higher.
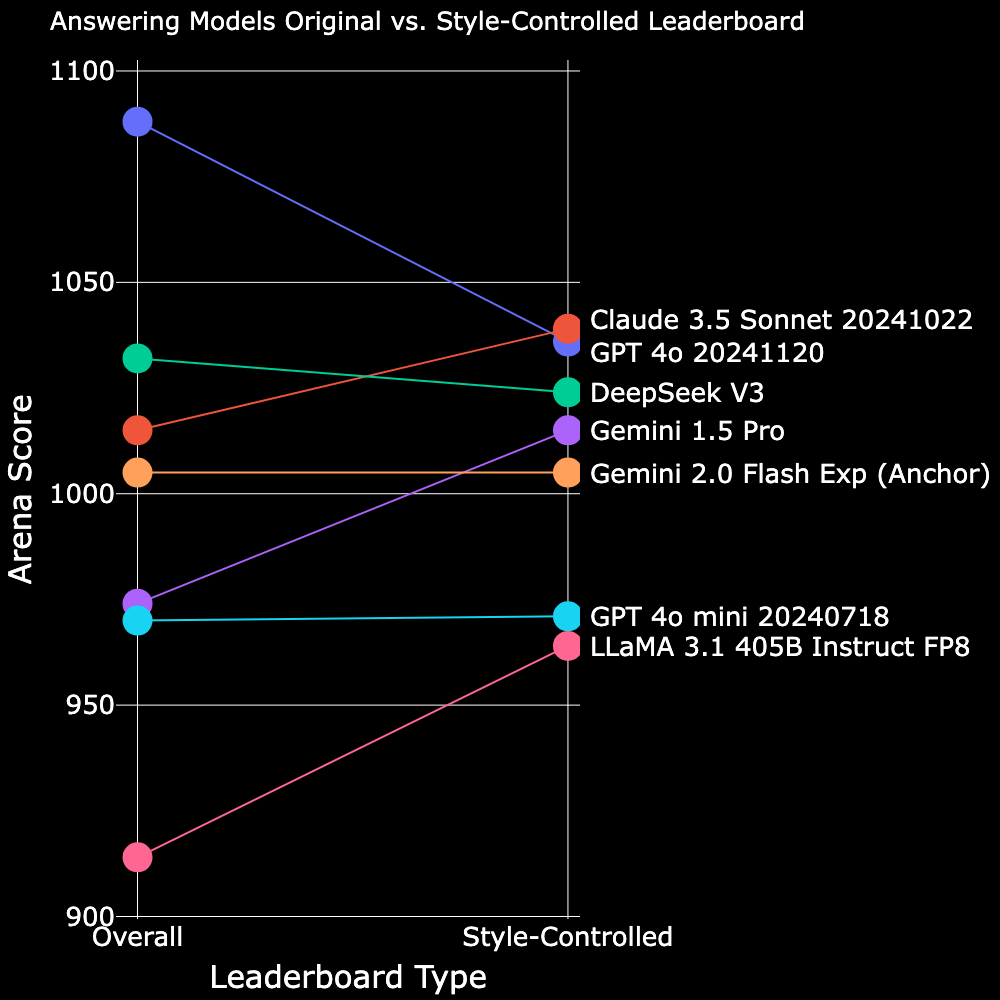
Why does style control affect models like Claude and GPT 4o so much?
This is likely because a significant portion of user queries are not focused on strictly code-writing tasks. Instead, many focus on code understanding—such as how to use the repository, its purpose, or other high-level questions—rather than specific code implementations. These types of queries shift the focus away from pure coding abilities, and instead place greater emphasis on organization and presentation, and overall style.
Below is an example battle between Claude 3.5 Sonnet (20241022) and GPT 4o (20241120) with identical retrievals.
The GitHub link is https://github.com/xtekky/gpt4free, and the user query is “Explain why in the new 0.4.0.0 version Blackbox provider is several times slower than in version 0.3.9.7”
Retriever Control
Just like style, the retrievers too have an effect on model answer. A model with with a more complete or relevant retrieval will likely produce a better answer. Similar to style-control, the retriever-controlled leaderboard separates the effect of the retrievers from the answer model ranking.
^ Table 5. Retriever-controlled arena ratings of the answer models.
The retriever-controlled leaderboard shows only slight differences from the original, as the two chosen retrievers perform similarly and have little influence on the rankings
Style + Retriever Control
^ Table 6. Style-and-retriever-controlled arena ratings of the answer models.
Leaderboard Calculation
How do we get separate leaderboards for the retrievers and the answer models from one set of battles? Extra features!
Chabot Arena leverages the Bradley-Terry model for scoring model strength using pairwise battles. We adopt its statistical extension to evaluate the additional subparts–the retrievers–by integrating them as extra features just like the answer models. Each retriever feature takes values from {-1, 0, 1}, indicating whether it was active in the file retrieval for model_a, neither/both, or model_b, respectively. By performing Logistic Regression on these additional retriever features along with the original model features, we obtain coefficients that are later scaled to become the leaderboard scores.
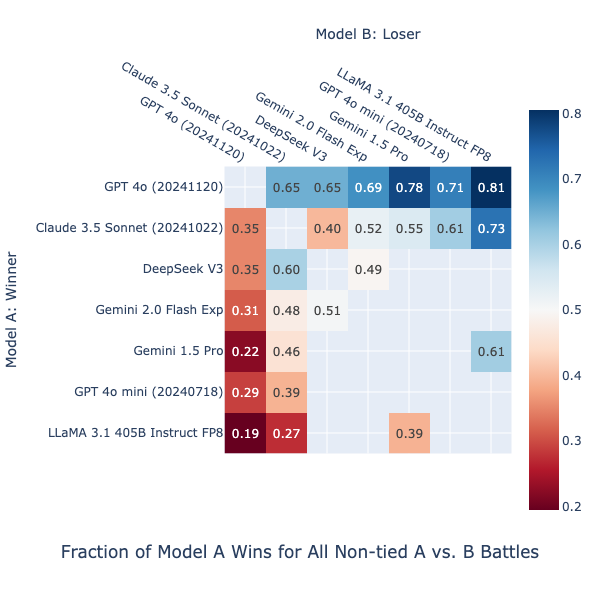
What’s Next?
We are actively collecting more votes and integrating new models, with plans for more comprehensive analysis down the line. Additionally, we are exploring ways to enhance RepoChat by incorporating features such as support for private repositories, GitLab integration, and improvements to our retrieval process. Community contributions are welcome—feel free to ping us if you’d like to get involved!
Appendix
- High level questions about a repository:
- https://github.com/lllyasviel/ControlNet
“Explain” - https://github.com/remix-run/react-router
“How to use this repo?”
- https://github.com/lllyasviel/ControlNet
- Specific how-to questions:
- https://github.com/leecig/OpenDevin/tree/main
“How do I use a local LLM being ran by LMStudio?” - https://github.com/ohmyzsh/ohmyzsh/
“Tell me, what it means and how to use thekubectx_mappingin the plugins/kubectx?”
- https://github.com/leecig/OpenDevin/tree/main
- Implementation requests:
- https://github.com/varungodbole/prompt-tuning-playbook
“Help me design a system prompt to extract metrics from financial reports.” - https://github.com/ocaml/ocaml
“If I wanted to implement partial escape analysis, which of the OCaml Intermediate Representations would be best suited and where should I make the change?”
- https://github.com/varungodbole/prompt-tuning-playbook
- Specific explanation requests:
- https://github.com/ant-design/ant-design
“Why does Ant Design 5 decide to use CSS-in-JS?” - https://github.com/celzero/rethink-app
“How are connection/network changes handled?”
- https://github.com/ant-design/ant-design
- Requests for solving an issue:
- https://github.com/HALF111/calibration_CDS
“Solve this issue.” - https://github.com/pyca/cryptography/issues/7189
“Using asyncssh can fix the immediate loading error for the PEM file, but when accessingcert.extensionsit still errors out with the same ordering issue.”
- https://github.com/HALF111/calibration_CDS
- Requests for reviewing a PR: - https://github.com/fairy-stockfish/Fairy-Stockfish/pull/758
“Review this PR.” - https://github.com/ggerganov/llama.cpp/pull/10455
“What type of speculative decoding is supported with this pull request? “ - Queries with code snippets, requests for modifying existing code, and debugging: (click the arrow to expand the full query)
https://github.com/julien-blanchon/arxflix/tree/feat/groq_whisper
when using the gradio interface, the stage of generating video get me this error :
INFO:__main__:Generated assets successfully.
INFO:backend.main:Generating video to output.mp4 from tmpmpc_r1vm
Free port: 55427
Exposed directory /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm
Starting up http-server, serving /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm
http-server version: 14.1.1
http-server settings:
CORS: true
Cache: 3600 seconds
Connection Timeout: 120 seconds
Directory Listings: visible
AutoIndex: visible
Serve GZIP Files: false
Serve Brotli Files: false
Default File Extension: none
Available on:
http://localhost:55427
Hit CTRL-C to stop the server
INFO:backend.utils.generate_video:Exposed directory /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm
INFO:backend.utils.generate_video:Generating video to /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm/output.mp4
(node:93666) ExperimentalWarning: CommonJS module /opt/homebrew/lib/node_modules/npm/node_modules/debug/src/node.js is loading ES Module /opt/homebrew/lib/node_modules/npm/node_modules/supports-color/index.js using require().
Support for loading ES Module in require() is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
Bundled code ━━━━━━━━━━━━━━━━━━ 550ms
[Fri Dec 06 2024 00:02:39 GMT+0100 (Central European Standard Time)] "GET /audio.wav" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/131.0.6778.87 Safari/537.36"
(node:93654) [DEP0066] DeprecationWarning: OutgoingMessage.prototype.\_headers is deprecated
(Use `node --trace-deprecation ...` to show where the warning was created)
Composition Arxflix
Codec h264
Output /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm/output.mp4
Concurrency 1x
Rendering frames ━━━━━━━━━━━━━━━━━━ 0/2353
Encoding video ━━━━━━━━━━━━━━━━━━ 0/2353[Fri Dec 06 2024 00:02:39 GMT+0100 (Central European Standard Time)] "GET /subtitles.srt" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/131.0.6778.87 Safari/537.36"
[Fri Dec 06 2024 00:02:39 GMT+0100 (Central European Standard Time)] "GET /rich.json" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/131.0.6778.87 Safari/537.36"
node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:187 Error: No "src" prop was passed to .
at ImgRefForwarding (http://localhost:3000/bundle.js:26884:15)
at Nh (http://localhost:3000/bundle.js:25838:137)
at Yi (http://localhost:3000/bundle.js:25870:57)
at Vk (http://localhost:3000/bundle.js:25971:275)
at Uk (http://localhost:3000/bundle.js:25957:389)
at Tk (http://localhost:3000/bundle.js:25957:320)
at Ik (http://localhost:3000/bundle.js:25957:180)
at Nk (http://localhost:3000/bundle.js:25948:88)
at Gk (http://localhost:3000/bundle.js:25945:429)
at J (http://localhost:3000/bundle.js:34117:203)
An error occurred while rendering frame 0:
Error No "src" prop was passed to .
at node_modules/.pnpm/remotion@4.0.171_react-dom@18.3.1_react@18.3.1__react@18.3.1/node_modules/remotion/dist/cjs/Img.js:19
17 │ const { delayPlayback } = (0, use_buffer_state_js_1.useBufferState)();
18 │ const sequenceContext = (0, react_1.useContext)(SequenceContext_js_1.SequenceContext);
19 │ if (!src) {
20 │ throw new Error('No "src" prop was passed to .');
21 │ }
22 │ (0, react_1.useImperativeHandle)(ref, () => {
at Nh (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:159)
at Yi (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:191)
at Vk (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:292)
at Uk (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:278)
at Tk (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:278)
at Ik (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:278)
at Nk (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:269)
at Gk (node_modules/.pnpm/react-dom@18.3.1_react@18.3.1/node_modules/react-dom/cjs/react-dom.production.min.js:266)
at J (node_modules/.pnpm/scheduler@0.23.2/node_modules/scheduler/cjs/scheduler.production.min.js:12)
at R (node_modules/.pnpm/scheduler@0.23.2/node_modules/scheduler/cjs/scheduler.production.min.js:13)
INFO:backend.utils.generate_video:Generated video to /var/folders/3j/jv5_hbgn59g9yxccxtfcvz4r0000gp/T/tmpmpc_r1vm/output.mp4
http-server stopped.
INFO:**main**:Generated video successfully.
^CKeyboard interruption in main thread... closing server.
bot.js
require("dotenv").config();
const { Telegraf, session } = require("telegraf");
const { registerCommands } = require("./commands");
const { registerHears } = require("./hears");
const { registerScenes } = require("./scenes");
const sequelize = require("./database");
const User = require("./models/user");
const { t, i18next } = require("./i18n");
const Plans = require("./models/plans");
// sync database
(async () => {
try {
await sequelize.sync({ force: true });
console.log("database synchronized successfully.");
const bot = new Telegraf(process.env.BOT_TOKEN);
const defaultPlan = await Plans.findOne({ where: { isDefault: true } });
if (!defaultPlan) {
await Plans.create({
name: "atom",
isDefault: true,
price: 0,
});
console.log("default plan created.");
}
// telegraf.js sessions
bot.use(
session({
defaultSession: () => ({ counter: 0, userName: "" }), // Initialize session variables
})
);
// user check/creation middleware
bot.use(async (ctx, next) => {
const telegramId = ctx.from.id;
try {
let user = await User.findOne({ where: { telegramId } });
if (!user) {
user = await User.create({
name: ctx.from.first_name || "unknown",
telegramId: telegramId,
});
console.log(
`new user created: ${user.name} (id: ${user.telegramId})`
);
}
ctx.session.isAuthorized = true;
ctx.session.user = user;
ctx.session.language = user.language || "ru";
i18next.changeLanguage(ctx.session.language);
return next();
} catch (error) {
console.error("error during user check/creation:", error);
return ctx.reply(t("error_user_creation"));
}
});
// register commands, hears, and scenes
registerCommands(bot);
registerHears(bot);
registerScenes(bot);
// start the bot
bot.launch();
console.log("bot is running.");
// enable graceful stop
process.once("SIGINT", () => bot.stop("SIGINT"));
process.once("SIGTERM", () => bot.stop("SIGTERM"));
} catch (error) {
console.error("error initializing bot:", error);
}
})();



