
The Multimodal Arena is Here!

You can now chat with your favorite vision-language models from OpenAI, Anthropic, Google, and most other major LLM providers to help discover how these models stack up against each other.
Contributors:
Christopher Chou*
Lisa Dunlap*
Wei-Lin Chiang
Ying Sheng
Lianmin Zheng
Anastasios Angelopoulos
Trevor Darrell
Ion Stoica
Joseph E. Gonzalez
We added image support to Chatbot Arena! You can now chat with your favorite vision-language models from OpenAI, Anthropic, Google, and most other major LLM providers to help discover how these models stack up against eachother.
In just two weeks, we have collected over 17,000 user preference votes across over 60 languages. In this post we show the initial leaderboard and statistics, some interesting conversations submitted to the arena, and include a short discussion on the future of the multimodal arena.
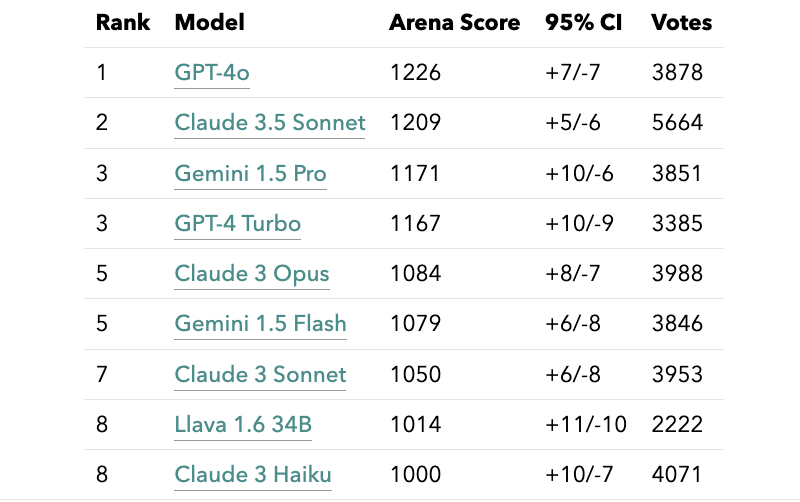
Leaderboard results
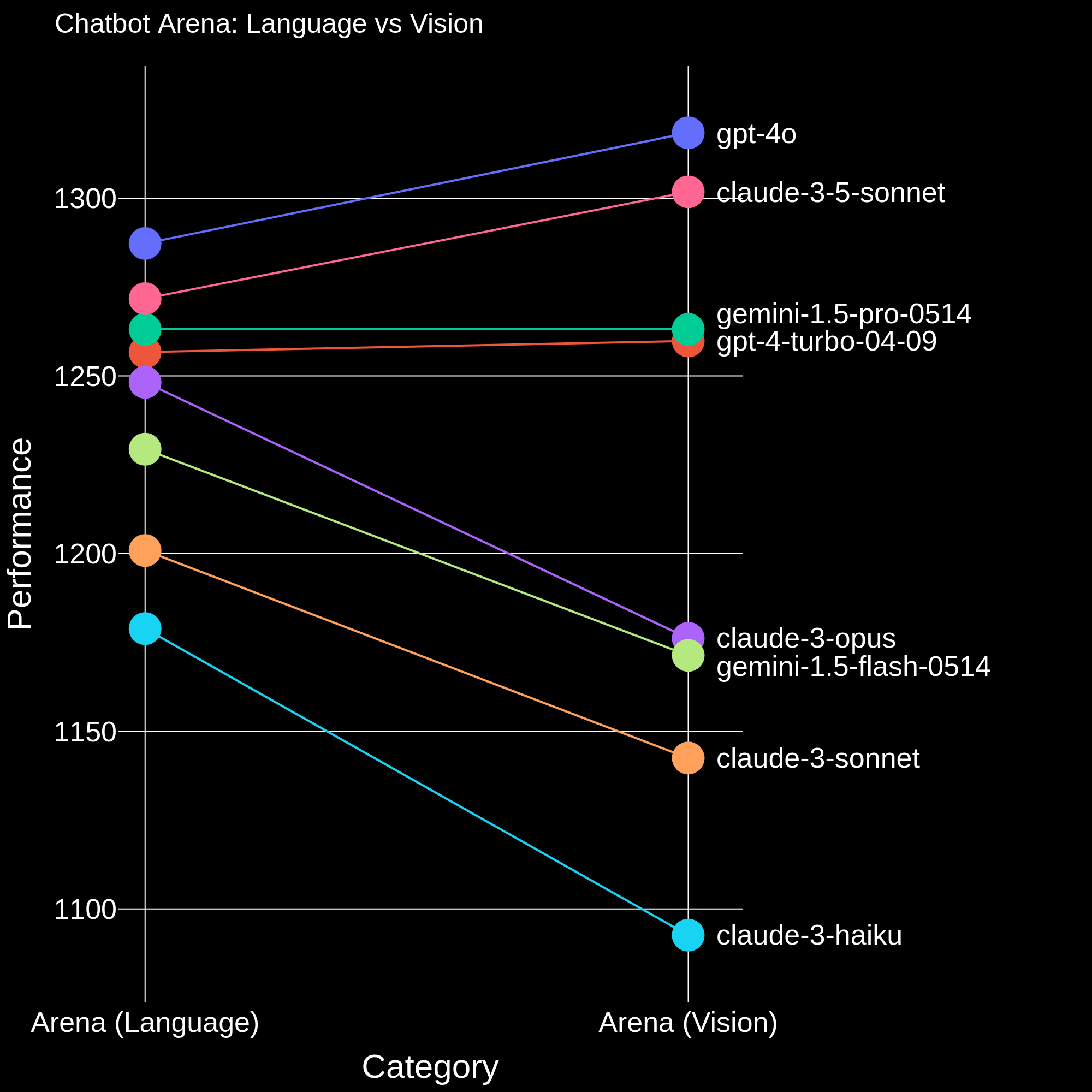
This multi-modal leaderboard is computed from only the battles which contain an image, and in Figure 1 we compare the ranks of the models in the language arena VS the vision arena. We see that the multimodal leaderboard ranking aligns closely with the LLM leaderboard, but with a few interesting differences. Our overall findings are summarized below:
- GPT-4o and Claude 3.5 achieve notably higher performance compared to Gemini 1.5 Pro and GPT-4 turbo. This gap is much more apparent in the vision arena compared to the language arena.
- While Claude 3 Opus achieves significantly higher performance than Gemini 1.5 flash on the LLM leaderboard but on the multimodal leaderboard they have similar performance
- Llava-v1.6-34b, one of the best open-source VLMs achieves slightly higher performance than claude-3-haiku.
As a small note, you might also notice that the “Elo rating” column from earlier Arena leaderboards has been renamed to “Arena score.” Rest assured: nothing has changed in the way we compute this quantity; we just renamed it. (The reason for the change is that we were computing the Bradley-Terry coefficients, which are slightly different from the Elo score, and wanted to avoid future confusion.) You should think of the Arena score as a measure of model strength. If model A has an Arena score sAsA and model B has an arena score sBsB, you can calculate the win rate of model A over model B as P(A beats B)=11+esB−sA400, where the number 400 is an arbitrary scaling factor that we chose in order to display the Arena score in a more human-readable format (as whole numbers). For additional information on how the leaderboard is computed, please see this notebook.
Examples of Multimodal Usage
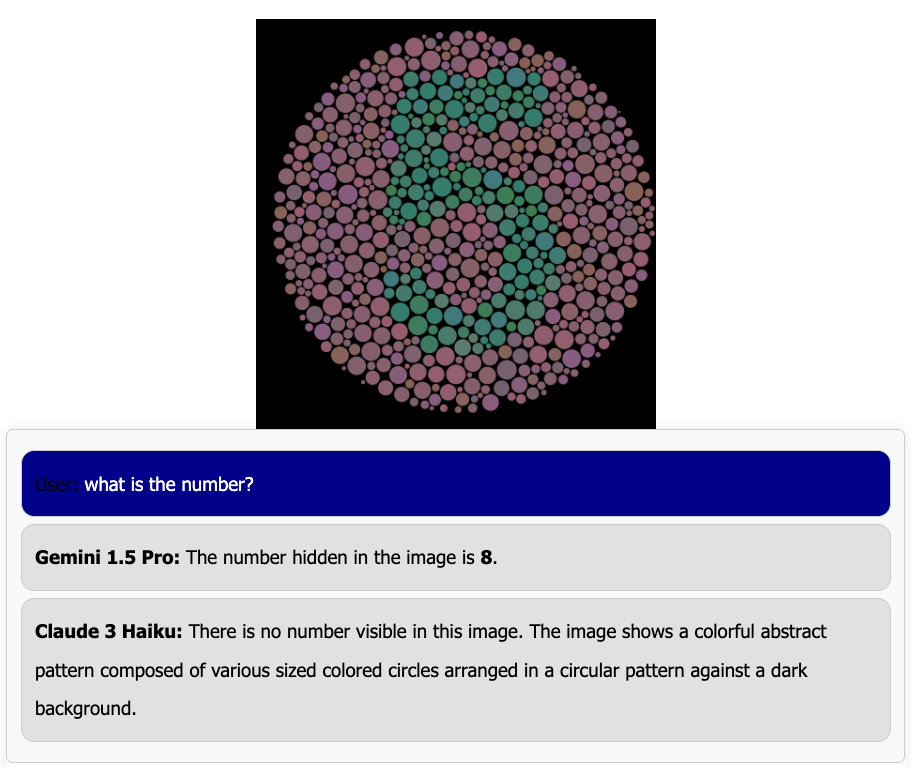
Now that we’ve looked at the leaderboard results, let’s look at some of the data! We are currently working to better group this data into categories, but these are some common tasks we have noticed so far:
- General captioning questions
- Math questions
- Document understanding
- Meme explanation
- Story writing
Note that we currently only consider conversations which pass our moderation filter. Below we have some examples from these categories as well as some other fun examples we found!








What’s next?
Along with rolling out some fun new categories for the multimodal leaderboard, we look forward to adding multi-image support and supporting new modalities such as PDFs, video, and audio. Please feel free to join our Discord and give us any feedback about what feature you want next!